
基于策略梯度的强化学习
强化学习可分为两大类:
-
value-based method(DP,MC,TD)
通过价值函数求解最优策略,求解出来的策略是确定性的,虽然可以通过$\epsilon$-贪心策略来获取一定的随机性。要求动作空间离散。
-
policy-based method
适用场景:随机策略;动作空间连续。
优点:具有更好的收敛性质。
缺点:通常会收敛到局部最优而非全局最优;评估一个策略通常不够高效并且具有较大的方差。
1.基本原理
由于策略实际上是一个概率分布,可以将策略参数化 $\pi(a|s,\theta)$ ,其中$\theta$ 是策略的参数。通过这种方式,可以将可见的已知状态泛化到未知的状态上。
1.1 策略目标函数
在片段式的环境中,使用每个经历片段(episode)的平均总回报。在连续性的环境中,使用每一步的平均奖励。


希望能够找到最大化$J(\theta)$的$\theta$,属于最优化问题,求解方法如下:
- 不使用梯度的方法(Hill climbing, Simplex, 模拟退火, 遗传算法)
- 使用梯度的方法更高效(梯度下降, 共轭梯度, 拟牛顿法)
1.2 策略函数
- softmax策略,离散型动作空间
- 高斯函数策略,连续型动作空间
- 线性函数策略,连续型动作空间,表示给定状态下确定性的动作,$a=\pi(s,\theta)$




1.3 单步马尔可夫决策过程
从一个分布d(s)中采样得到一个状态s,从s开始,按照策略𝜋采取一个行为a,得到即时奖励$r=R_{s,a}$。由于是单步过程,目标函数为
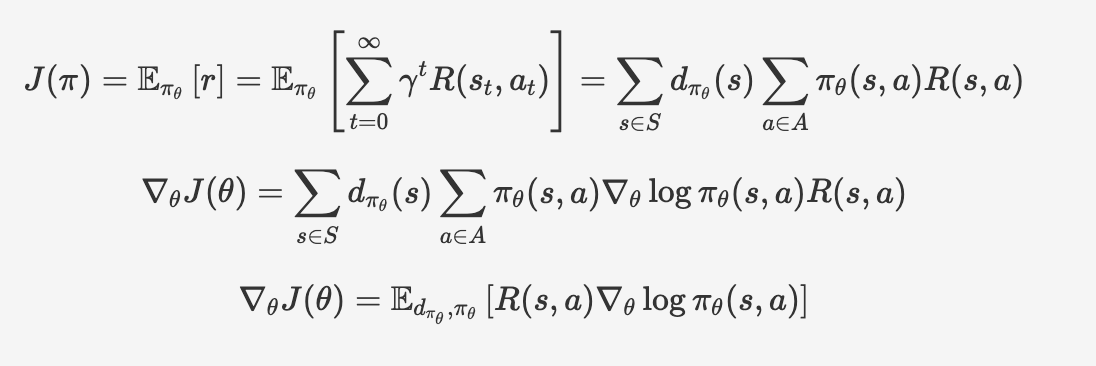
2.策略梯度定理


由于状态转移函数的存在,虽然训练用的轨迹都是由同一个策略生成的,但其两两差异仍十分显著,并且显然轨迹越长差异越大,决策中每一个微小的差异累积起来都会导致最后结果的极大差异。也就是数据有着较大的方差,这会导致使用均值计算期望的效果变差,并使算法难以收敛。
改进方法:使用时序因果关系;加入基线。




3.蒙特卡洛策略梯度(REINFORCE)


4. Actor-Critic 算法
actor --> policy network,决定采取哪个动作
- $\pi(a|s;\theta)$
- input: state s
- output: probability distribution over the actions
- 训练目标: 增加状态值函数 state-value
critic --> value network,只负责评估动作的好坏
- $q(s,a;w)$
- input: state s and action a
- output: approximate action-value(scalar)
- 训练目标: 使价值评估的更精准,接近于实际环境的return


参考资料:
中国科学院大学林姝老师 强化学习课程课件
深度强化学习:基础、研究与应用 (董豪 等)
https://mp.weixin.qq.com/s/y1Rj3fIaXkNjEyakCqRSIg
Reinforcement Learning An Introduction (Adaptive Computation and Machine Learning series) (Sutton, Richard S., Barto, Andrew G.)