
强化学习基础知识
知识点:马尔科夫决策过程,动态规划。
马尔科夫决策过程
马尔科夫过程: 一个具备马尔科夫性质的离散随机过程。
马尔科夫性: 下一时刻的状态只与当前状态有关。即$P[S_{t+1}|S_{1},…,S_{t}]=P[S_{t+1}|S_{t}]$
马尔科夫奖励函数: 把马尔科夫过程从 <S, P> 拓展到 <S, P, R, γ>。其中P 为状态转移矩阵,R 和 γ 分别表示奖励函数和奖励折扣因子。折扣因子越大,代表了智能体对长期性能指标考虑的程度越高(远视);折扣因子越小,代表了智能体对长期性能指标考虑的程度越低(近视)。
回报: 回报是一个轨迹的累积奖励,$G_{t} = R_{t+1} + \gamma R_{t+2} = \sum_{k=0}^{\infty } \gamma ^{k}R_{t+k+1}$
价值函数:状态s的期望回报,$V(s) = E[G_{t}|S_{t}=s]$。
马尔科夫决策过程: 马尔可夫奖励过程的立即奖励只取决于状态(奖励值在节点上),而马尔可夫决策过程的立即奖励与状态和动作都有关。即把马尔科夫过程从 <S, P, R, γ> 拓展到 <S, A, P, R, γ>。A是有限动作的集合。
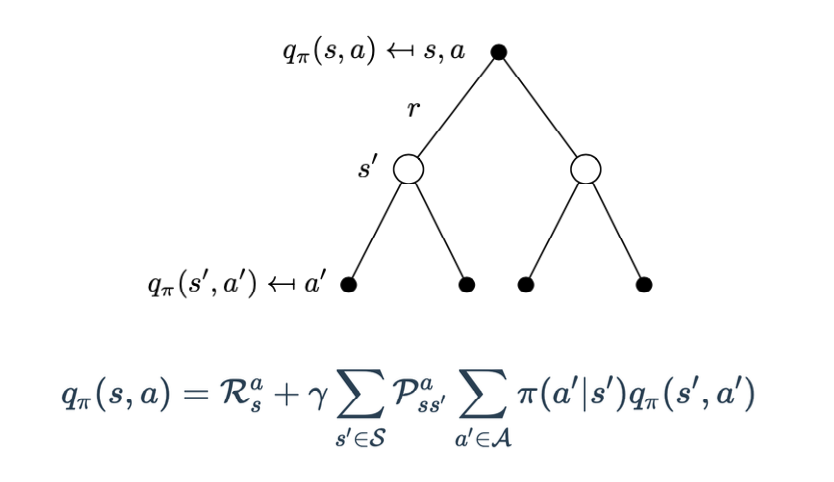
动作价值函数: 依赖于状态和刚刚执行的动作,是基于状态和动作的期望回报。$Q(s,a) = E[G_{t}|S_{t}=s, A_{t}=a]$。易知$V(s)=E_{a}[Q(s,a)]$。
策略: 状态到行为的映射。
对于任何马尔科夫决策过程:
- 总是存在一个最优策略$\pi^*$,比任何其他策略更好或至少相等。
- 所有的最优策略有相同且最优的价值。
- 所有的最优策略具有相同且最优的动作价值。
贝尔曼方程:用于计算给定策略 π 时价值函数在策略指引下所采轨迹上的期望。
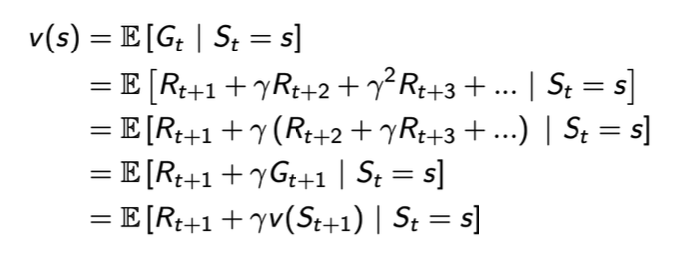
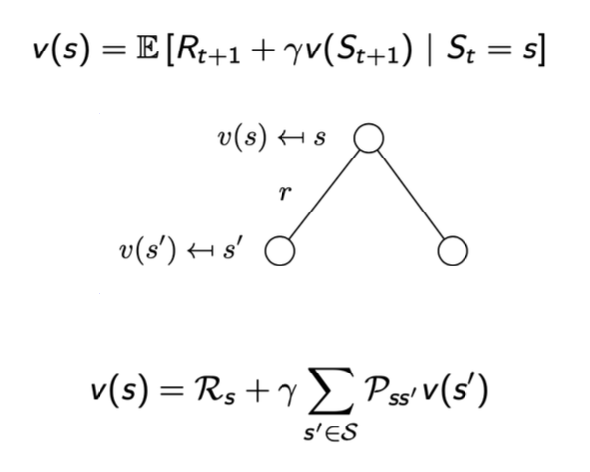
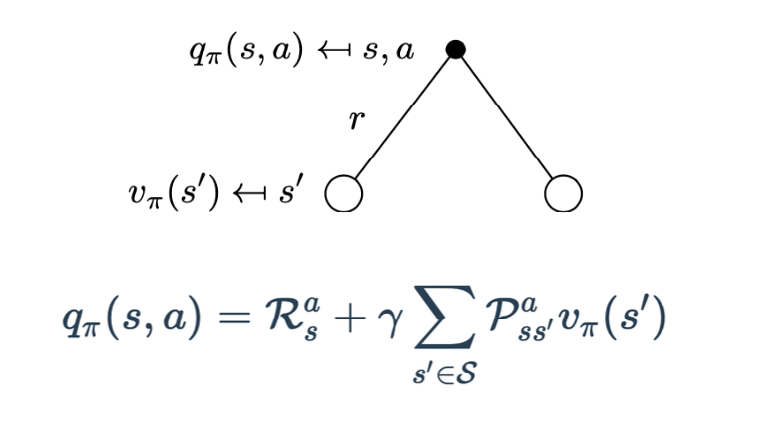
最优价值函数:
即使是在相同的状态和动作集合上,不同的策略也将会带来不同的价值函数。定义最优价值函数为
$$v_*(s) = \max_{π} v_π(s), ∀s ∈ S$$
最优动作价值函数:
$$q_*(s,a) = \max_{\pi} q_π(s,a), ∀s ∈ S, a ∈ A$$
则
$$v*(s) = \max_{a\sim \mathbf{A}} q_*(s, a)$$
$$q_(s, a) = E[R_t + γv_(S_{t+1}) | S_t = s, A_t = a]$$
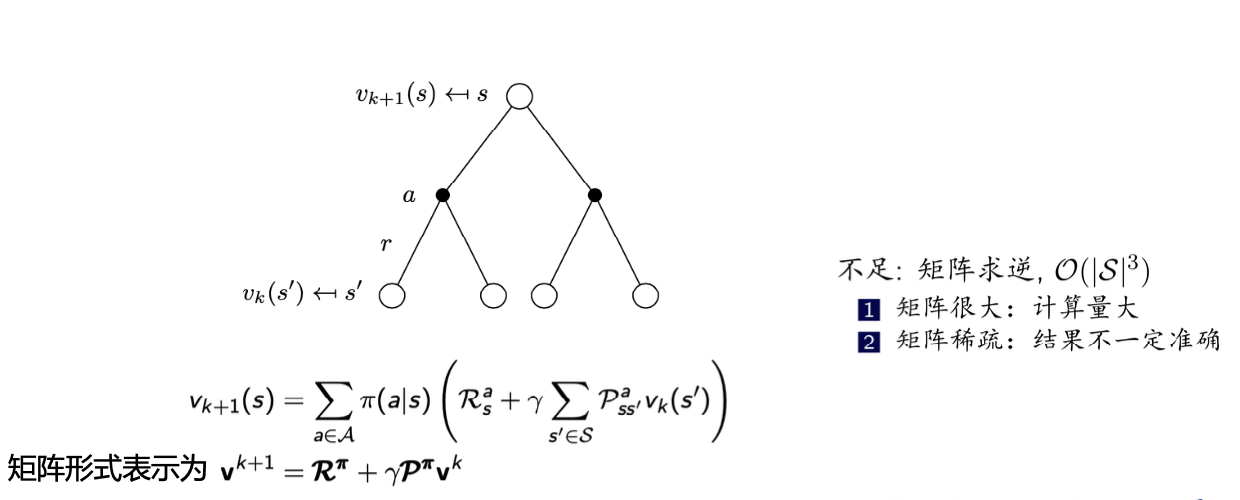
逆矩阵法求解贝尔曼方程:
$$\mathbf{v} = \mathbf{r} + γP\mathbf{v} $$
其中 v 和 r 矢量,P是状态转移概率矩阵。求解如下:
$$\mathbf{v} = (I − γP )^{-1}\mathbf{r}$$
复杂度为$O(n^{3})$,考虑其他方法进行求解,如动态规划、蒙特卡洛估计、时序差分法等。
动态规划
用动态规划算法在 能够获取MDP完整的环境信息(包括状态动作空间、转移矩阵、奖励等)的基础上 求解最优策略。
预测:给定一个MDP <𝒮, 𝒜, 𝒫, ℛ, 𝛾>和策略𝜋,输出基于当前策略𝜋的价值函数v。
控制:给定一个MDP <𝒮, 𝒜, 𝒫, ℛ, 𝛾>,输出最优价值函数𝑣∗以及最优策略𝜋∗
迭代策略评估: 预测问题,评估一个给定的策略$\pi$。

策略迭代:
- 策略评估,在当前策略𝜋上迭代地计算𝑣值
- 策略更新,根据𝑣值贪婪地更新策略
- 如此反复多次,最终得到最优策略𝜋∗和最优状态价值函数𝑣∗

价值迭代:

参考资料:
中国科学院大学 林姝老师 强化学习课程课件
深度强化学习:基础、研究与应用 (董豪 等)
Reinforcement Learning An Introduction (Adaptive Computation and Machine Learning series) (Sutton, Richard S., Barto, Andrew G.)