
搜索
知识点:
经典搜索算法:基于路径的搜索的问题。如盲目搜索,启发式搜索。
局部搜索算法:最优化问题,没有初始状态,也没有终止状;并不需要到达这些解的路径。如爬山法,元启发算法。
元启发式算法是启发式算法的改进,它是随机算法与局部搜索算法相结合的产物。如禁忌搜索算法(Tabu Search),模拟退火算法(Simulated annealing),遗传算法(Geneticalgorithm)。
对抗搜索算法:也被称为博弈搜索,在一个竞争的环境中,智能体(agents)之间通过竞争实现相反的利益,一方最大化利益,另外一方最小化这个利益。如mini-max算法,Alpha-Beta算法、蒙特卡洛树。
1.搜索算法基础
树搜索:
- 结点:n.state, n.parent, n.action(父节点生成该节点时所采取的行动), n.path-cost(从初始状态到达该结点的路径消耗g(n))
- 搜索策略:节点扩展到顺序
- 策略评价标注:完备性(是否能找到存在的解),时间复杂度,空间复杂度,最优性
- 复杂度表示:分支因子b,搜索树的中节点的最大分支树;深度d,目标结点所在的最浅深度;m,状态空间中,任何路径的最大长度
图搜索:
- 边缘(fringe):待扩展的叶子结点,将状态空间分成已探索区域和未被探索区域。
2.盲目搜索
只能使用访问过的结点的信息。如宽度优先搜索,深度优先搜索,一致代价搜索(扩展路径消耗g(n)最小的结点),深度受限搜索(对深度优先搜索设置最大深度的界限),迭代加深的深度优先搜索(不断增大深度限制,并且每次重新开始深度受限搜索)。

3.启发式搜索
优先扩展最优的结点。评价函数:f = g + h。其中,g为一致代价,h为启发式函数,指的是结点n到目标结点的最小代价路径的代价估计值。
- 贪婪算法:扩展离目标最近的结点,以期望很快找到解。f(n)=h(n)
- A* 算法:避免扩展代价已经很高的路径。f(n) = g(n) + h(n)
A* 算法:
可采纳启发式:永远不会高估代价,即$h(n)\le h^(n)$,且要求$h(n)\ge 0$。其中,$h^(n)$为实际的代价。
定理:如果h(n)是可采纳的,A*的树搜索版本是最优的。
一致的启发式:对于每个结点n和通过任一行动a生成的后继结点n’,从结点n到达目标的估计代价不大于从n到n’的单步代价与从n到目标的估计代价之和,即$h(n)\le c(n,a,n’) + h(n’)$。如果h(n)是一致的,那么沿着任何路径的f(n)是非递减的。
定理:如果h(n)是一致的,那么A*的图搜索版本是最优的。
松弛问题:对原问题移除一些限制,一个松弛问题的最优解的代价是原问题的一个可采纳、一致的启发式。
松弛问题的最优解的代价不大于原问题最优解的代价。
4.局部搜索
局部搜索:找到满足条件的状态,不关心路径,从单个当前节点(而不是多条路径)出发,通常只移动到它的邻近状态。
4.1 爬山法
属于贪婪法,不断向值增加的方向移动,容易到达局部极大值。为了克服局部极大值,可以采用随机重启爬山法,完备的概率接近1。
4.2 禁忌搜索算法
从一个初始可行解出发,选择一系列的特定搜索方向(移动)作为试探,选择实现让特定的目标函数值变化最多的移动。
为了避免陷入局部最优解,TS搜索中采用了一种灵活的“记忆”技术,对已经进行的优化过程进行记录和选择,指导下一步的搜索方向,这就是Tabu表的建立。
标记已经解得的局部最优解或求解过程,并在进一步的迭代中避开这些局部最优解或求解过程。局部搜索的缺点在于,太过于对某一局部区域以及其邻域的搜索,导致一叶障目。为了找到全局最优解,禁忌搜索就是对于找到的一部分局部最优解,有意识地避开它,从而或得更多的搜索区域。




4.3 模拟退火算法
算法概述:
- 若目标函数f在第i+1步移动后比第i步更优,即$f(Y(i+1))\le f(Y(i))$,则总是接受该移动。
- 若$f(Y(i+1))>f(Y(i))$,(即移动后的解比当前解要差),则以一定的概率接受移动,而且这个概率随着时间推移逐渐降低(逐渐降低才能趋向稳定)。
- Metroplis准则:温度越高,算法接受新解的概率就越高。


4.4 遗传算法
基本思想:从初始种群出发,采用优胜劣汰、适者生存的自然法则选择个体,并通过杂交、变异来产生新一代种群,如此逐代进化,直到满足目标为止。
- 种群:组候选解的集合,遗传算法正是通过种群的迭代进化,实现了最优解或者近似最优解。
- 个体:一个个体对应一个解,也就是构成种群的基本单元。
- 适应度函数:用来对种群中各个个体的环境适应性进行度量的函数,函数值是遗传算法实现优胜劣汰的主要依据。
- 遗传操作:作用于种群而产生新的种群的操作。如选择、交叉、变异。
遗传编码:
- 二进制编码
- 格雷编码,要求两个连续整数的编码之间只能有一个码位不同,其余码位都是完全相同的。
- 符号编码,个体染色体编码串中的基因值取自一个无数值含义、而只有代码含义的符号集
适应度函数:
- 原始适应度函数,直接将待求解问题的目标函数f(x)定义为遗传算法的适应度函数。它能够直接反映出待求解问题的最初求解目标但是有可能出现适应度值为负的情况。
- 标准适应度函数。在遗传算法中,一般要求适应度函数非负,并其适应度值越大越好。这就往往需要对原始适应函数进行某种变换,将其转换为标准的度量方式,以满足进化操作的要求,这样所得到的适应度函数被称为标准适应度函数$f_{Normal}(x)$
选择:各个个体被选中的概率与其适应度大小成正比
- 比例选择
- 锦标赛选择,随机选择一组个体进行竞赛,然后从中选择最优秀的个体来进行繁殖。
- 轮盘赌选择,根据每个个体的选择概率$P(x_i)$将一个圆盘分成N 个扇区,其中第i 个扇区的中心角为:$2 \pi \frac{f\left(x_{i}\right)}{\sum_{j=1}^{N} f_{i}\left(x_{j}\right)}=2 \pi p\left(x_{i}\right)$,并再设立一个固定指针。当进行选择时,可以假想转动圆盘,若圆盘静止 时指针指向第i个扇区,则选择个体i。
交叉:
- 单点交叉,先在两个父代个体的编码串中随机设定一个交叉点,然后对这两个父代个体交叉点前面或后面部分的基因进行交换,并生成子代中的两个新的个体。
- 两点交叉,先在两个父代个体的编码串中随机设定两个交叉点,然后再按这两个交叉点进行部分基因交换,生成子代中的两个新的个体。
- 多点交叉,从两个父代个体中选择多个交叉点,然后交换这些交叉点之间的基因片段,从而产生新的个体。
- 均匀交叉,父串中的每一位都是以相同的概率随机进行交叉的。
实值交叉,在实数编码情况下所采用的交叉操作,可分为部分离散交叉、整体交叉。
部分离散交叉: 先在两个父代个体的编码向量中随机选择一部分分量, 然后对这部分分量进行交换,生成子代中的两个新的个体。
整体交叉: 对两个父代个体的编码向量中的所有分量,都以1/2的概率进行交换,从而生成子代中的两个新的个体。
- 洗牌交叉,打乱之后再选择交叉点,再进行复原
变异:
- 二进制变异,随机地产生一个变异位,0->1,1->0
- 实值变异,用另外一个在规定范围内的随机实数去替换原变异位置上的基因值,产生一个新的个体。
5.对抗搜索
5.1 Alpha-Beta算法
对mini-max算法的改进。剪枝本身不影响算法输出结果,但节点先后次序会影响剪枝效率。
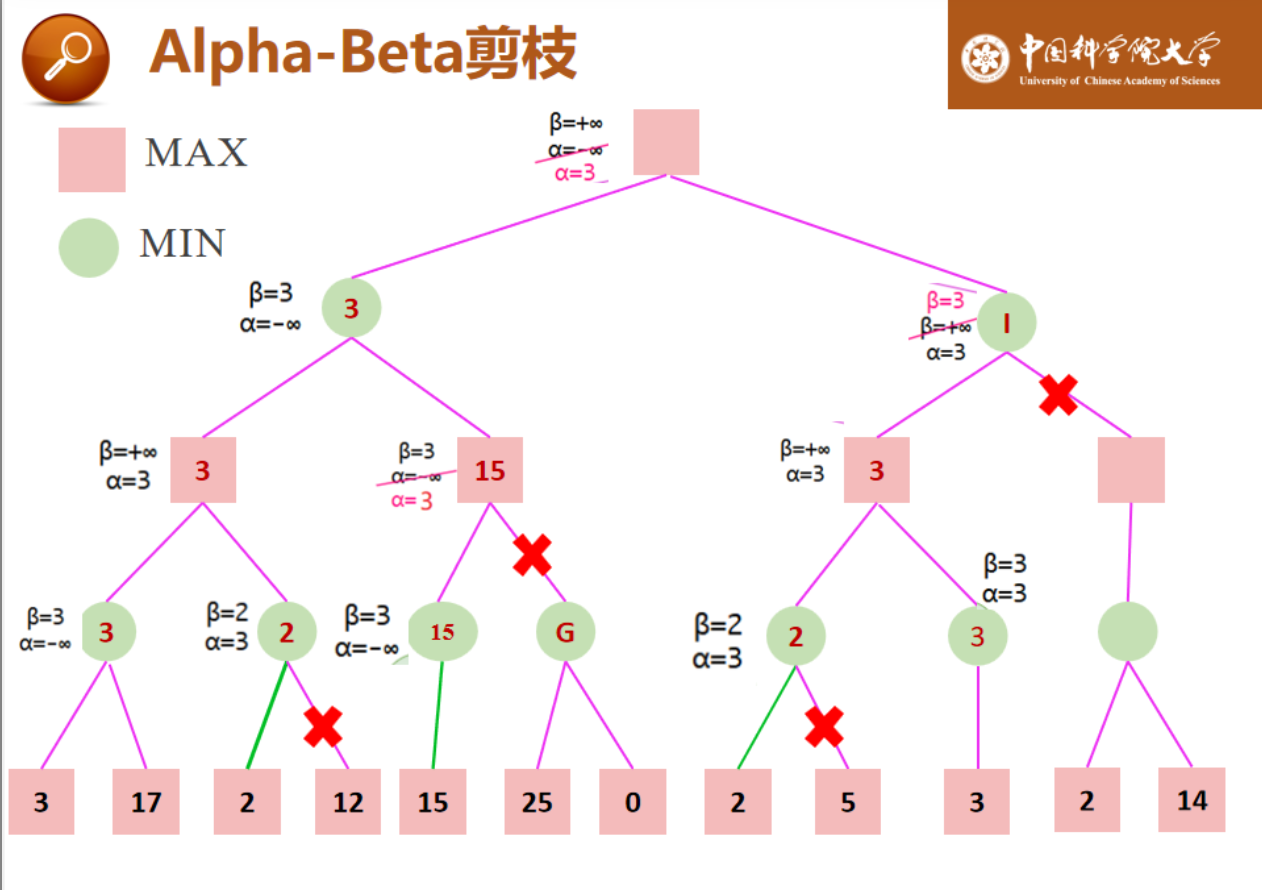

5.2 蒙特卡洛树
参看蒙特卡洛树搜索部分。
6.参考资料
中国科学院大学李国荣老师 高级人工智能课程课件
高级算法设计与分析 启发式算法 林海老师