
无模型强化学习
知识点
1.无模型价值学习评估
- 蒙特卡洛方法
- 时序差分学习
- TD(𝝀)
2.无模型策略优化控制
- 蒙特卡洛策略迭代
- 时序差分策略迭代(SARSA)
- Q值迭代 (Q-learning)
1. 无模型价值学习评估
1.1 蒙特卡洛方法
蒙特卡洛方法是一种基于样本的方法,不需要知道环境的所有信息。只需基于过去的经验就可以学习。具体来说,给定一个策略 π,通过对 π 产生的回报取平均值来评估状态价值函数。这样就有两种估算方式: 首次蒙特卡罗(First-Visit Monte Carlo)和每次蒙特卡罗(Every-Visit Monte Carlo)。首次蒙特卡罗只考虑每一个回合中第一次到状态 s 的访问,而每次蒙特卡罗就是考虑每次到状态 s 的访问。
注意的是,和动态规划不同的是,蒙特卡罗不使用自举(Bootstrapping),也就是说,它不用其他状态的估算来估算当前的状态值。

离线学习:智能体从预先收集好的数据中进行学习。
在线学习:智能体通过与环境实时交互来获取知识和经验。
1.2 时序差分学习
时序差分学习方法同蒙特卡洛方法一样是不基于模型的,不需要马尔可夫决策过程的知识。但是时序差分学习方法可以直接从经历的不完整经历片段中学习,它通过自举(bootstrap)猜测经历片段的结果并不断更新猜测。即时序差分学习方法可以在每一次经历的过程中进行学习,而蒙特卡洛方法只能等到每次经历完全结束时才能进行学习。
\[𝑉(𝑆_{𝑡}) ← 𝑉(𝑆_{𝑡}) + 𝛼(𝐺_t − 𝑉(𝑆_{𝑡}))\]
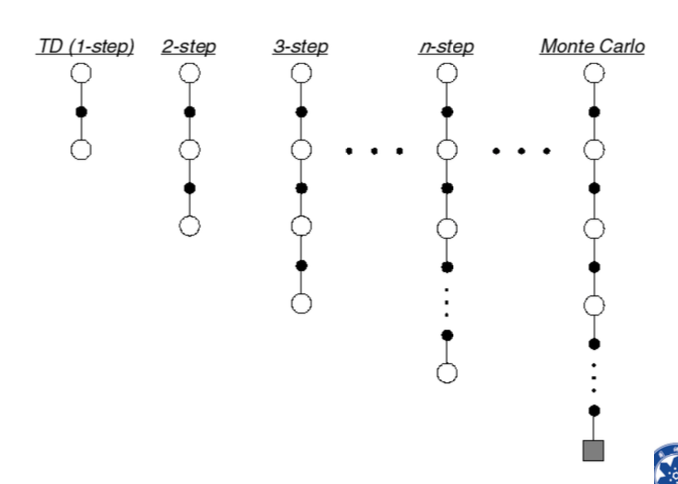
对TD(0),即one-step TD:
\[𝑉(𝑆_{𝑡}) ← 𝑉(𝑆_{𝑡}) + 𝛼(𝑅_{𝑡+1} + 𝛾𝑉(𝑆_{t+1}) − 𝑉(𝑆_{𝑡}))\]

这个算法又被叫做SARSA,因为用到了 \((S_t, A_{𝑡}, R_{𝑡+1}, S_{𝑡+1}, A_{𝑡+1})\)。
- 蒙特卡洛方法没有偏倚,是对当前状态实际价值的无偏估计,但有着较高的变异性,且对初始值不敏感。
- 时序差分方法方差更低, 但有一定程度的偏差,对初始值较敏感,通常比蒙特卡洛方法更高效。
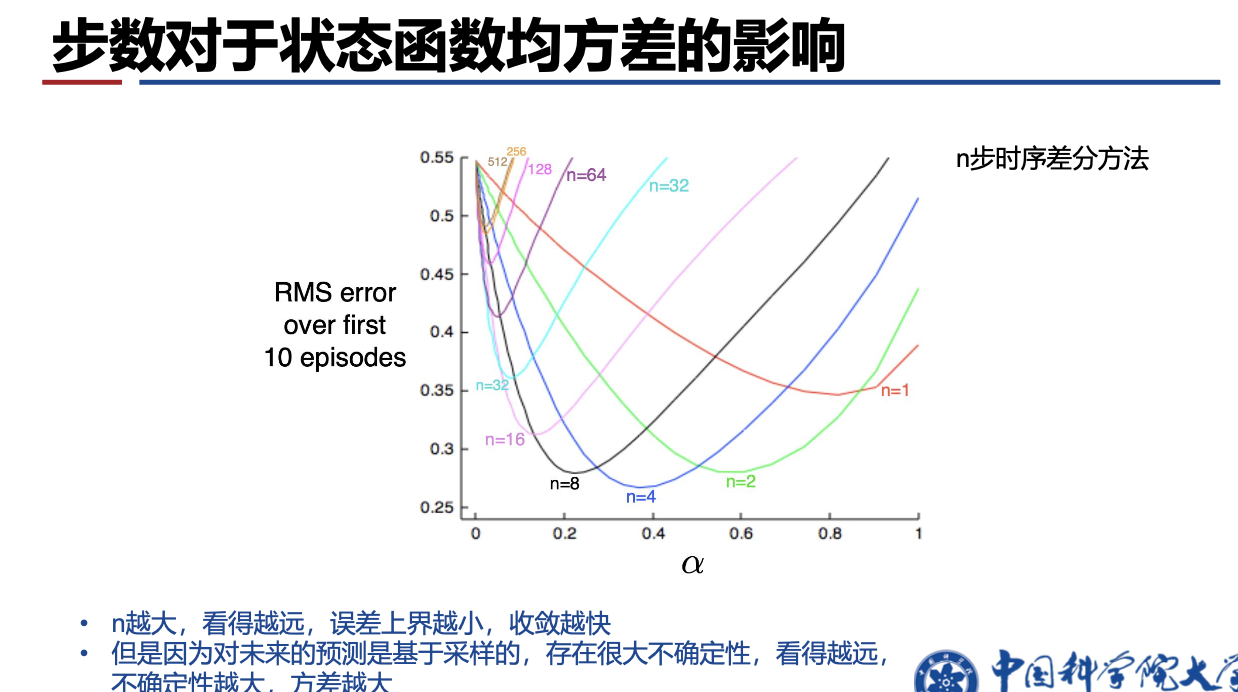
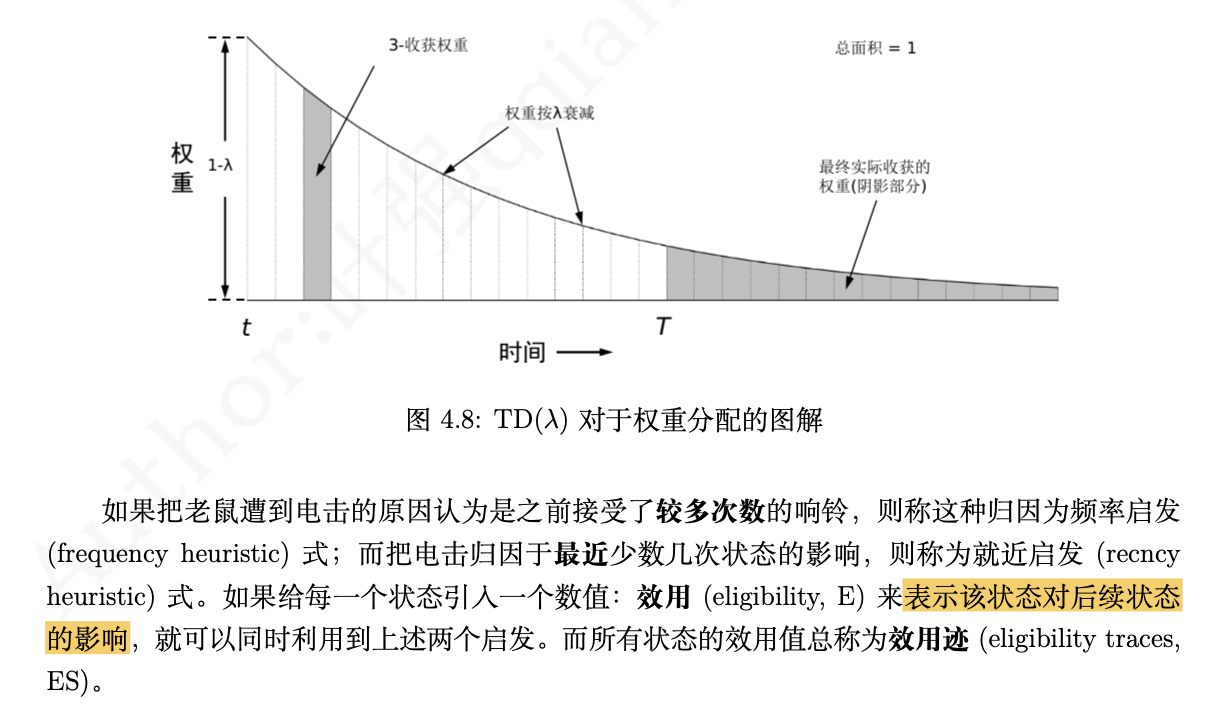
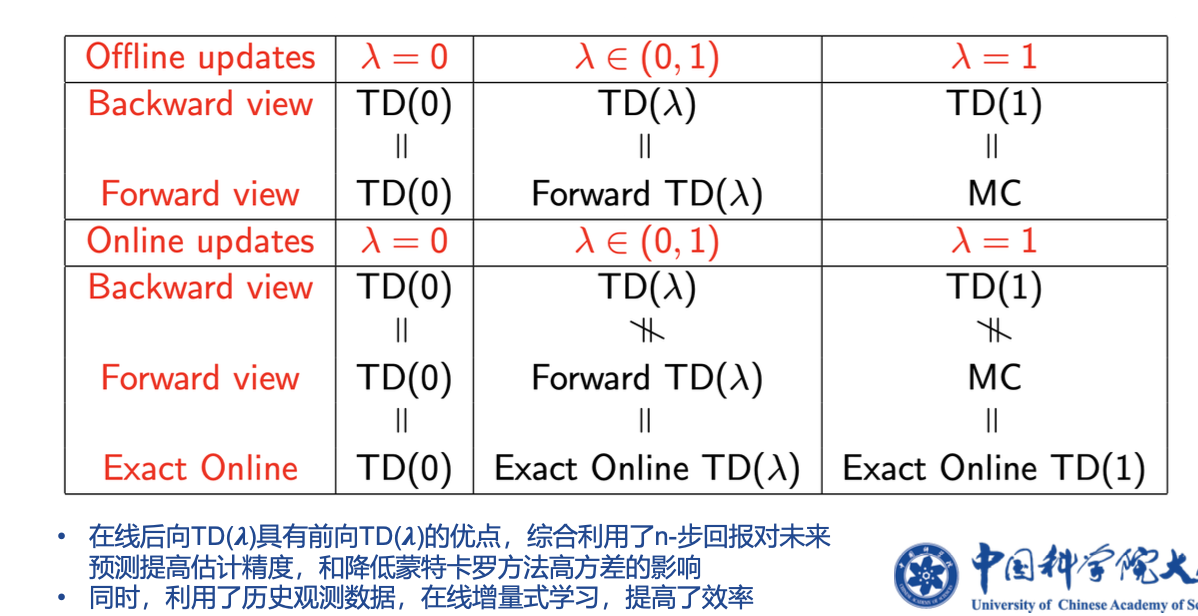
1.3 TD(𝝀)




2.无模型策略优化控制
2.1 蒙特卡洛策略迭代

2.2 时序差分策略迭代(SARSA)
\[G_{t:t+n} = R_{t+1} + γR_{t+2} + \dot + γ^{n−1}R_{t+n} + γ^nQ_{t+n−1}(S_{t+n}, A_{t+n})\]


2.3 Q值迭代 (Q-learning)
Sarsa --> on-policy
Q-learning --> off-policy

参考资料:
中国科学院大学林姝老师 强化学习课程课件
深度强化学习:基础、研究与应用 (董豪 等)
强化学习入门——从原理到实践,叶强
Reinforcement Learning An Introduction (Adaptive Computation and Machine Learning series) (Sutton, Richard S., Barto, Andrew G.)