
深度强化学习
强化学习从深度学习角度出发的挑战:
- 强化学习的奖励信号是有延迟的,而深度学习的输入输出是直接联系的
- 强化学习的序贯决策序列有很高的相关性,而深度学习的假设数据是独立同分布
- 强化学习的数据分布是会随着学习发生变化的,而深度学习的假设是底层分布固定的
1. DQN算法
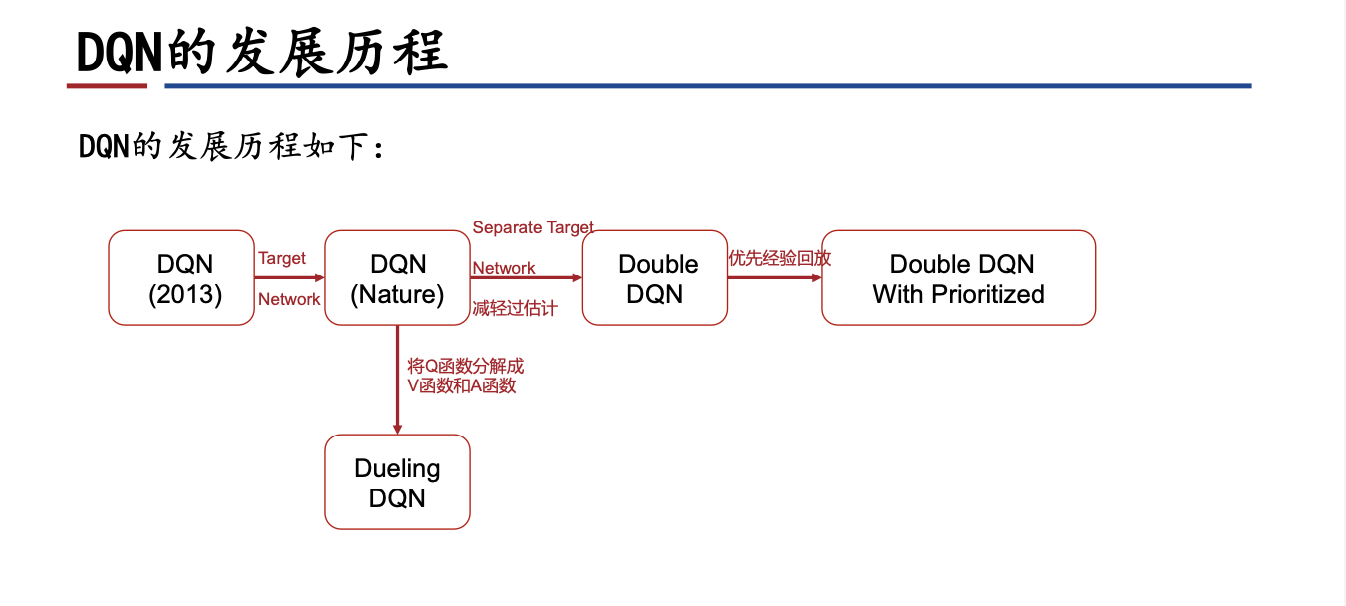
1.1 DQN
Deep Q-learning: DQN, Approximate $Q^*(s,a)$ by DQN,$Q(s,a;w)$
经历回放(experience replay): 在每个时间步t 中,DQN先将智能体获得的经验$(S_t, A_t, R_t, S_{t+1})$存入回放缓存中,然后从该缓存中均匀采样小批样本用于 Q-Learning 更新。主要作用是解决数据的相关性和非静态分布问题。
DQN2015的改进:增加目标网络。目标网络通过使用旧参数生成 Q-Learning 目标,使目标值的产生不受最新参数的影响,从而大大减少发散和震荡的情况。



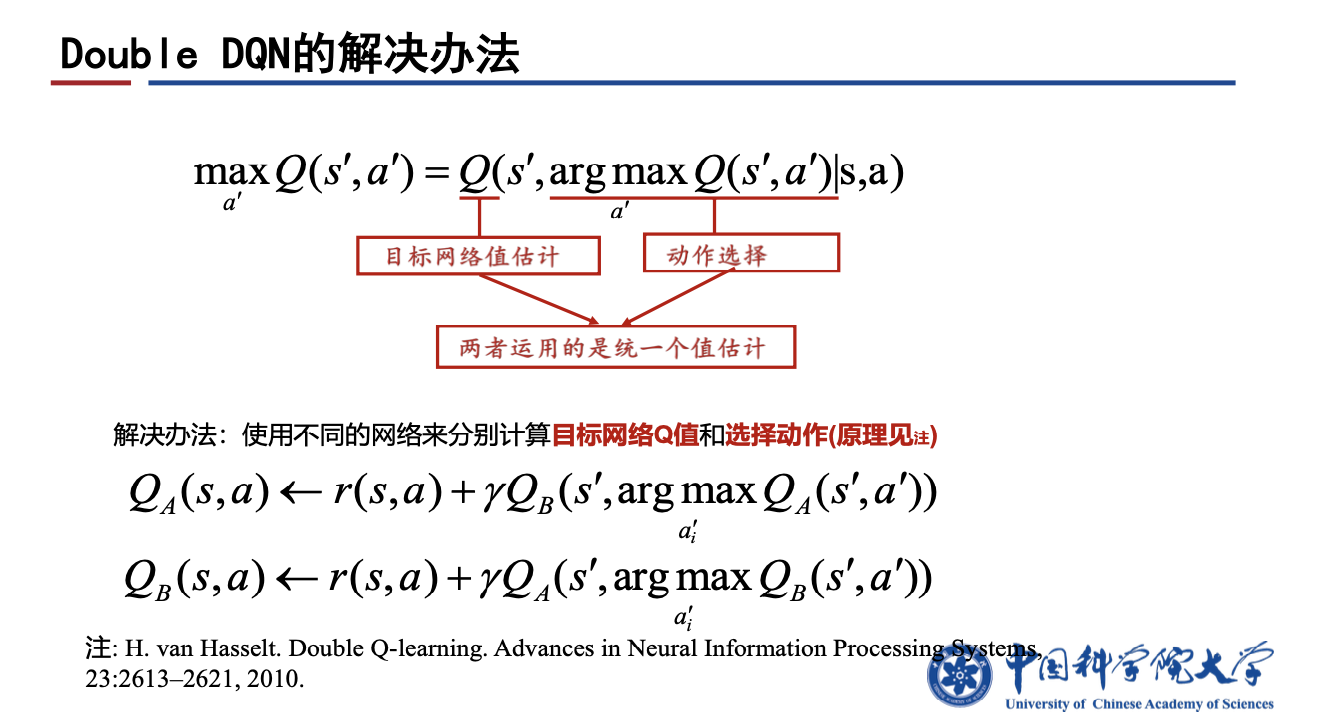
1.2 Double-DQN, DDQN
Double DQN 是对 DQN 在减少过拟合方面的改进。这是由于DQN对动作值函数的max操作会引入一个正向的偏差,导致下一时刻的目标值存在过估计。

1.3 Prioritized Experience Replay, 优先经验回放
采用优先级采样达到收敛所需的更新次数相比均匀采样要小很多,这也是进行优先经验池回放的原因。
1.3.1 样本优先级:
样本优先级应满足两个条件:
- 优先级在数值上应该和误差绝对值成单调递增关系,这是为了满足误差绝对值较大(即优先级较大)的样本获得更大的被抽样的机会;
- 优先级数值应大于0,这是为了保证每一个样本都有机会被抽样,即抽样概率大于0。
优先级可以分为基于比例的样本优先级,基于排序的样本优先级。如下图所示:

1.3.2 随机优先级采样:
采样方法:
- 贪婪优先级采样,完全按照优先级去采样
- 一致随机采样,均匀采样
- 随机优先级采样,随机采样
基本原则:
- 样本被采样的概率应该和样本优先级成正相关关系
- 每一个样本都应该有机会被采样,即被采样的概率大于0
Sum-Tree随机优先级采样,属于基于比例的样本优先级:
重要性采样: 用一个分布来计算当前分布的期望。

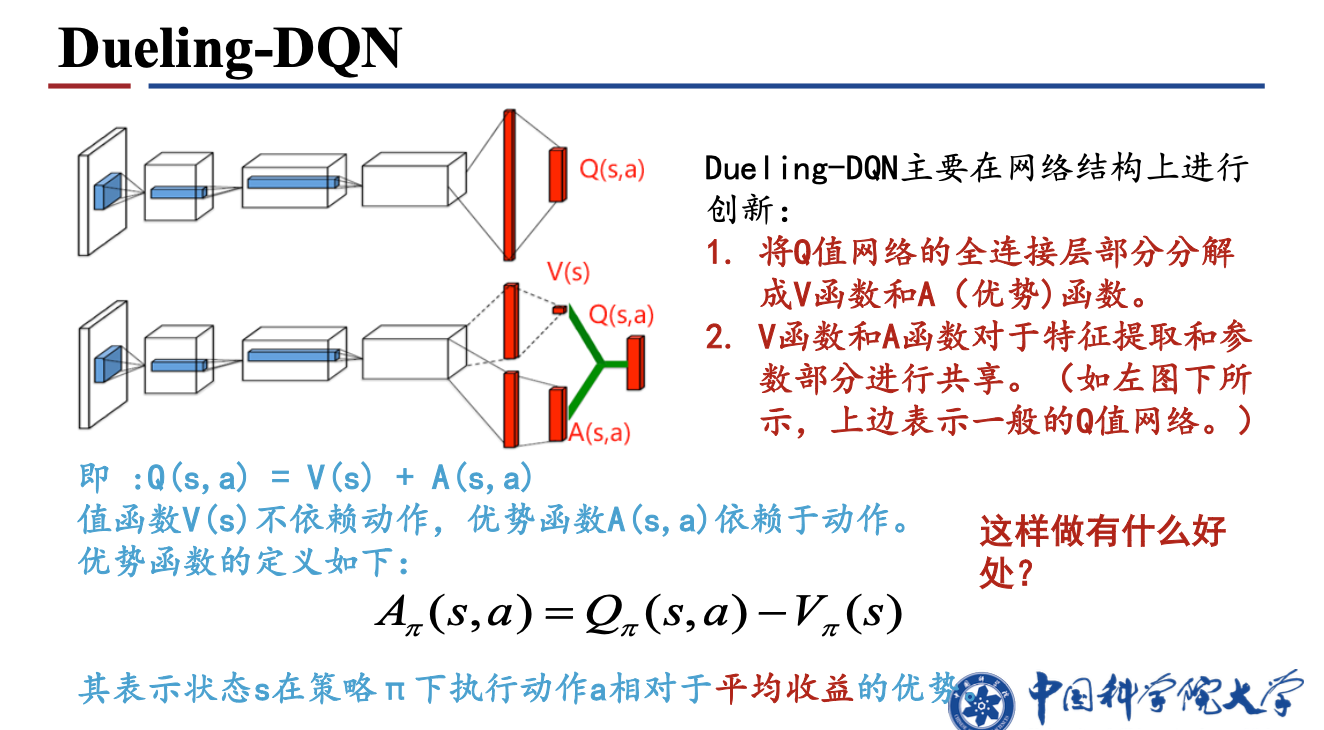
1.4 Dueling-DQN
算法原理:将动作值的计算分解成状态值和优势函数,$Q(s,a)=V(s)+A(s,a)$。

2. 策略梯度方法DDPG
2.1 DPG, (Deterministic Policy Gradient) 确定性策略梯度
确定性策略:每一步的动作都是确定的,即$a=\mu_\theta(s)$。确定性策略梯度算法正是使用了确定性策略的策略梯度算法。
2.2 DDPG, (Deep Deterministic Policy Gradient)

几个trick:
- $\mu^{\prime}(s_t)=\mu(s_t|\theta_{t}^{\mu} + N)$ 添加了一个随迭代次数衰减的随机噪声,增加了动作空间的探索
- 目标网络缓慢更新保证了训练的稳定性
- batch normalization 使得可以在不同的环境中获取的特征统一
问题:值函数过估计;自举造成的偏差传播
2.3 PPO

2.4 SAC, (Soft Actoe Critic)
熵:随机变量取各值时信息量的期望。

参考资料:
中国科学院大学林姝老师 强化学习课程课件
深度强化学习:基础、研究与应用 (董豪 等)
Reinforcement Learning An Introduction (Adaptive Computation and Machine Learning series) (Sutton, Richard S., Barto, Andrew G.)