
知识获取
信息抽取:从自然语言文本中抽取指定类型的实体、关系、事件等事实信息,并形成结构化数据输出的文本处理技术。
1.命名实体识别
1.1 基于词典的方法
典型方法包括正向匹配方法,反向匹配方法。原理:按照一定的策略将待分析的汉字串与一个充分大的词典中的词条进行匹配,若在词典中找到某个字符串,则匹配成功。
1.2 基于统计的方法
- 生成式方法,首先建立学习样本的生成模型,再利用模型对预测结果进行间接推理,如HMM。
- 判别式方法,基于由字构词的命名实体识别理念,将NER问题转化为判别式分类问题(序列标注问题),如Maxent,SVM,CRF,CNN,RNN,LSTM+CRF。CRF做解码善于捕捉近距离的标签依赖,LSTM可以捕捉长距离的标签依赖。
1.3 基于大模型的方法
难点1: 任务形式差距。命名实体识别通常建模为序列标注任务,而大模型往往用于完成文本
生成任务。难点2: 大模型存在较为严重的幻觉问题。
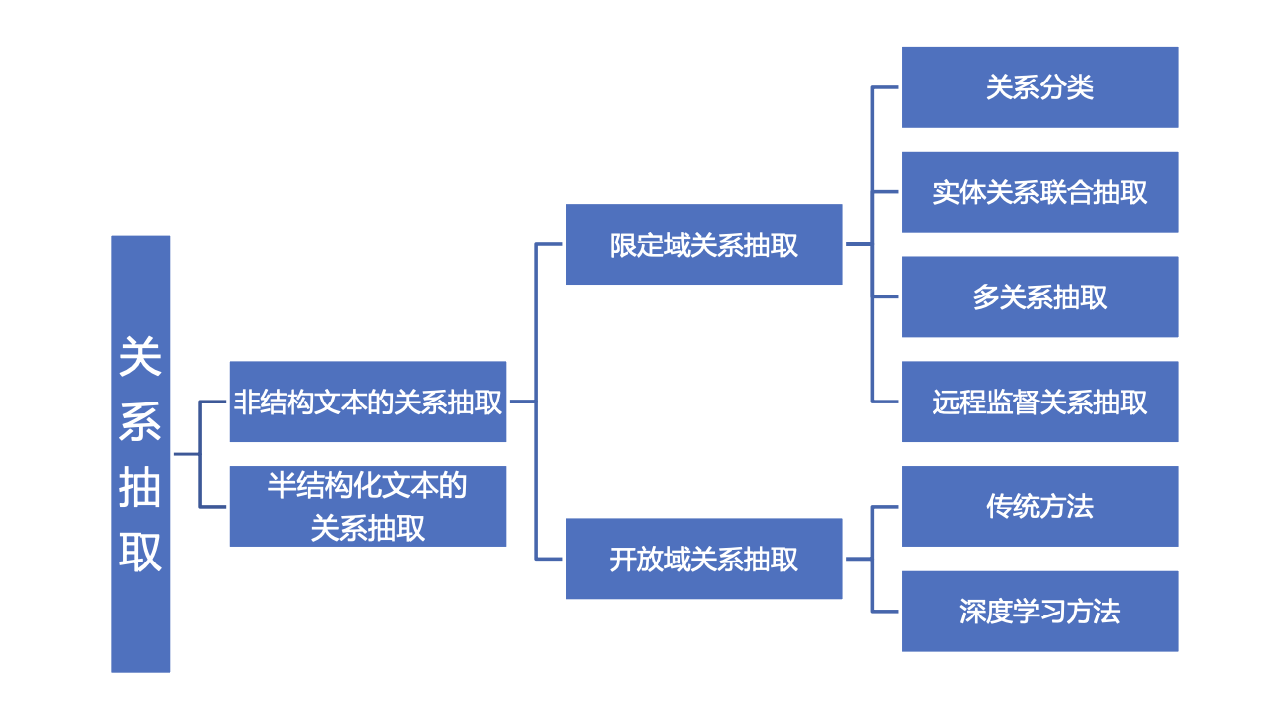
2.关系知识抽取
关系抽取:旨在自动识别由一对概念和联系这对概念的关系构成的相关三元组。如CEO(比尔盖茨,微软)。
3.事件知识抽取
事件是发生在某个特定的时间点或时间段、某个特定的地域范围内,由一个或者多个角色参与的一个或者多个动作组成的事情或者状态的改变。
事件关系:共指,时序,因果,子事件。
4.参考资料
中国科学院大学赵军老师 知识工程课程课件
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.