
知识计算
一. 命题逻辑
1.1 基本概念
知识库:KB, 利用形式化语言定义的句子的集合。
逻辑:用于表示信息的形式化语言。
语法:句子的形式化结构。
语义:语句在每个可能模型中的真值。
模型: m, m是语句 \(\alpha\) 的一个模型,表示语句在模型m 中为真,也称m 满足 \(\alpha\)。
逻辑:用于表示信息的形式语言。
逻辑蕴涵:某语句在逻辑上跟随另一个语句,如 \(\alpha \models \beta\),当且仅当在 \(\alpha\) 为真的模型中,\(\beta\) 也为真,即 \(M(\alpha) \subseteq M(\beta)\)。同样的,对于知识库 \(KB \models \alpha\),则有 \(M(KB) \subseteq M(\alpha)\)。如果算法i 可以根据KB推导出 \(\alpha\),记为 \(KB\vdash _i \alpha\)。
可靠性:只能生成被蕴含的语句。即永远不会返回一个错误的结果。
完备性:生成所有被蕴含的语句。即返回的结果总能覆盖所有正确的解。
命题逻辑:应用一套形式化规则对以符号表示的描述性陈述进行推理的系统。
原子命题:一个或真或假的描述性陈述语句,并且无法再分解为更简单的命题


理解:\(S_1\) 不成立时,相当于 \(S_1\) 为空集,空集可以被其他所有集合包含,因此 \(S_1\) 不成立时 \(S_1 \Rightarrow S_2\) 为真。
逻辑等价:命题p 和命题q
在所有情况下都具有相同的真假结果。 
有效性:一个句子在所有模型中都为真,则句子是有效的。
可满足性:一个句子在某些模型中为真。
1.2 归结原理
合取范式,也被称为CNF范式,以文字析取式的合取式表达的语句。

假言推理
在命题逻辑中,归结规则是可靠的、完备的。
反证法:证明:\(KB\vdash \alpha\),只需证明\(KB\wedge \neg \alpha\)不可满足。
子句集S 的归结闭包\(RC(S)\):对S 中的子句或其派生子句反复使用归结规则而生成的所有子句的集合。
限定子句:是受限形式的一种,它是指恰好只有一个正文字的析取式。
Horn子句:包含至多一个正文字的析取式。用Horn子句判定蕴涵需要的时间与知识库的大小呈线性关系。如前向链接与反向链接。
前向链接:如果蕴含式的所有前提已知,那么就把它的结论添加到已知事实集,真到查询q 被添加或者无法进一步推理。
反向链接:从查询q 开始推理。如果查询q 为真,那么无须任何操作。否则寻找知识库中那些能以q 为结论的蕴含式。如果其中某个蕴含式的所有前提都能证明为真,那么q 为真。
二. 谓词逻辑
命题逻辑的局限性: 在命题逻辑中,每个陈述句是最基本的单位(即原子命题),无法对原子命题进行分解。因此,在命题逻辑中,不能表达局部与整体、一般与个别的关系,即使不同原子命题蕴含个体、群体和关系等内在丰富语义。
谓词逻辑:将原子命题进一步细化,分解出个体、谓词和量词,来表达个体与总体的内在联系和数量关系。
谓词:刻画个体属性或者描述个体之间关系存在性的元素,值域为{True,False}。
量词:全称量词 \(\forall\),存在量词 \(\exists\)。
量词对偶:全称量词与存在量词可以相互转换,互相表示。
三. 不确定性推理
效用:对不同决策结果的偏好。决策理论 = 概率理论 + 效用理论。
不确定性推理:从不确定的初始证据出发,通过运用不确定性知识,推导出具有一定程度不确定性但合理的结论的思维过程。
贝叶斯网:一个有向无环图模型,用简单的条件分布描述复杂的联合分布。其中,每个结点有一个条件概率分布\(P(X_i | Parents(X_i))\),量化其父结点对该结点的影响。所有条件概率构成条件概率表。
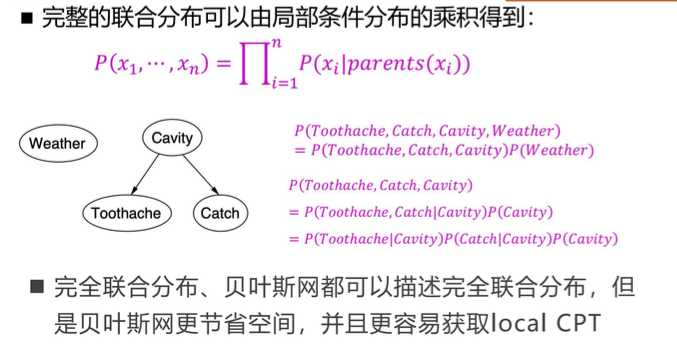
贝叶斯网独立条件:一个结点的概率只与其父结点有关,与其它祖先结点无关。判断贝叶斯网是否独立可以利用贝叶斯球快速判断(通过、反弹、截止)。
马尔科夫毯:一个结点的父结点、子结点、子结点的父结点。
贝叶斯球算法:
假设在贝叶斯网络中有一个按一定规则运动的球。已知中间结点 (或结点集合)Z,如果球不能由结点X 出发到达结点Y (或者由Y 到X ),则称X 和Y 关于Z 独立。
通过: 父结点->当前结点 方向的球,访问当前结点的任意子结点。子结点->当前结点 方向的球,访问当前结点的任意父结点。即父->子,子->父 。
反弹:父结点->当前结点 方向的球,访问当前结点的任意父结点。子结点->当前结点 方向的球,访问当前结点的任意子结点。即父->父,子->子。
截止:当前结点阻止贝叶斯球继续运动。
贝叶斯球规则:未知结点:父->子,子->父/子 。已知结点:父->父,子->截止。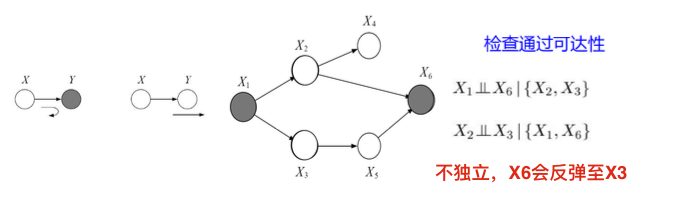
枚举推理(精确推理):所有的变量集合X ,所有的证据变量集合E ,查询变量Q ,隐藏变量集合H = X - E- Q。则\(P(Q|E=e)=\alpha P(Q,E=e)=\alpha\sum_{H=h} (Q,E=e,H=h)\)
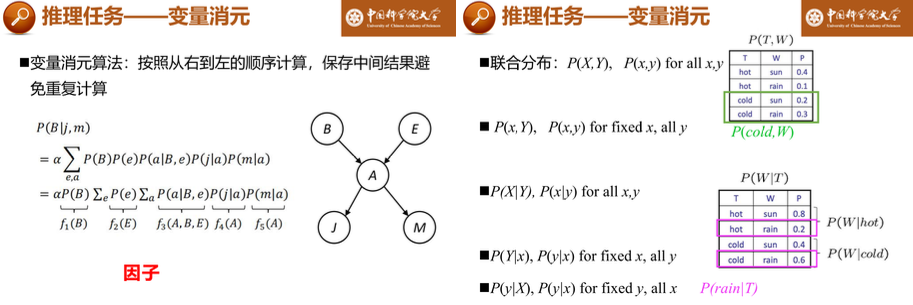
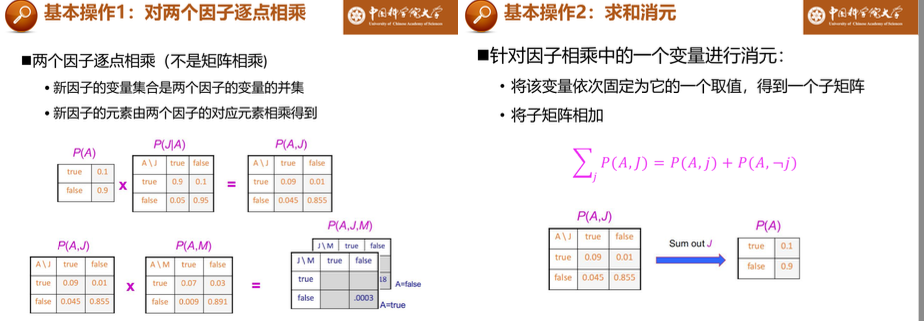

变量消元:降低贝叶斯网推理复杂度。
近似推理:抽取样本形成采样分布,通过该分布近似后验概率。
采样方法:
先验采样:按拓扑顺序进行采样,从$P(X_i | Parents(X_i))$采样$X_i$。
优点:简单直接,可以直接从已知的先验分布中抽样,计算方便。
缺点:不适用于高维空间,不适合于复杂模型。
拒绝采样:拒绝不符合证据E 的样本,即若$X_i$与观察值不一样,放弃这个样本。
优点:容易实现。
缺点:采样效率低,因为拒绝太多的样本,随着证据变量的增多,与证据相一致的样本数量指数级下降。
似然加权采样(重要性采样):只生成与证据一致的事件,即固定证据变量。但这会导致采样分布与实际分布不一致,因此正需要对样本进行加权,权重为该样本与证据的相似性。
优点:简单易实现,克服了拒绝采样的采样效率低的问题。
缺点:不适用于高维空间,即当证据变量的个数增加时,性能可能大幅下降。 因为大多数的样本权值都非常低/高。
吉布斯采样:固定证据变量,每次模拟一个隐藏变量的采样,从$X_i ~ P(X_i | 马尔可夫毯(X_i))$,使频率收敛到真实概率。
优点:在高维空间中通常比其他采样方法更有效,因为它逐维采样。适合于复杂模型。
缺点:收敛速度慢。依赖于条件独立性假设:需要模型条件分布容易计算。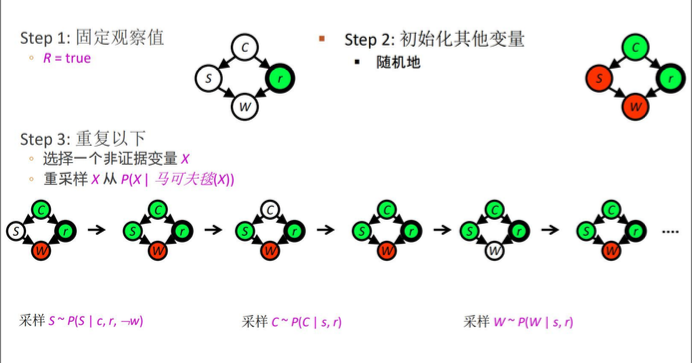
四. 参考资料
中国科学院大学高级人工智能,李国荣老师,课程课件