
数值化知识表示
语言模型发展四范式:形式语言模型,统计语言模型,神经语言模型,预训练语言模型。
课程复习使用。
一. 语言的分布表示
-
Harris分布假说:上下文相似的词,其语义也相似。认为词的语义可以根据上下文统计获得,词之间的相似性可以通过向量距离衡量。
-
word2vect: 词嵌入,上下文预测目标词
-
CBOW:目标词预测上下文。
二. 知识的分布表示
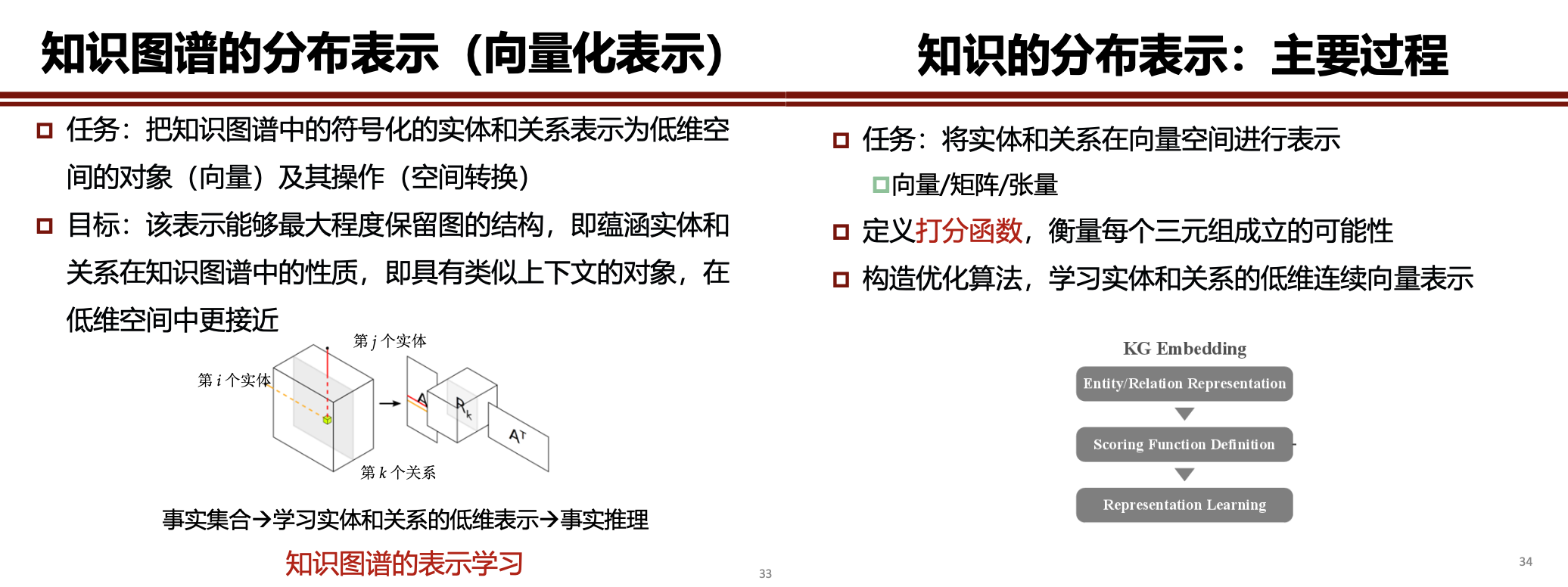
-
打分函数:
位移距离模型。位移距离模型 (translational distance models):基于位移假设,即头尾实体的表示存在位移关系,采用基于“头尾实体表示的位移”与“关系表示”的距离作为打分函数来衡量三元组成立的可能性。
语义匹配模型。无上述假设,直接利用头实体、关系和尾实体的数值表示进行计算,采用基于相似度的打分函数来衡量三元组成立的可能性。
-
模型训练:
封闭世界假设,但凡未在知识图谱中出现的事实都是错误的。
开放世界假设,知识图谱只包括正确的事实,那些不在其中出现的事实要么是错误的,要么是缺失的。
三. 预训练语言模型
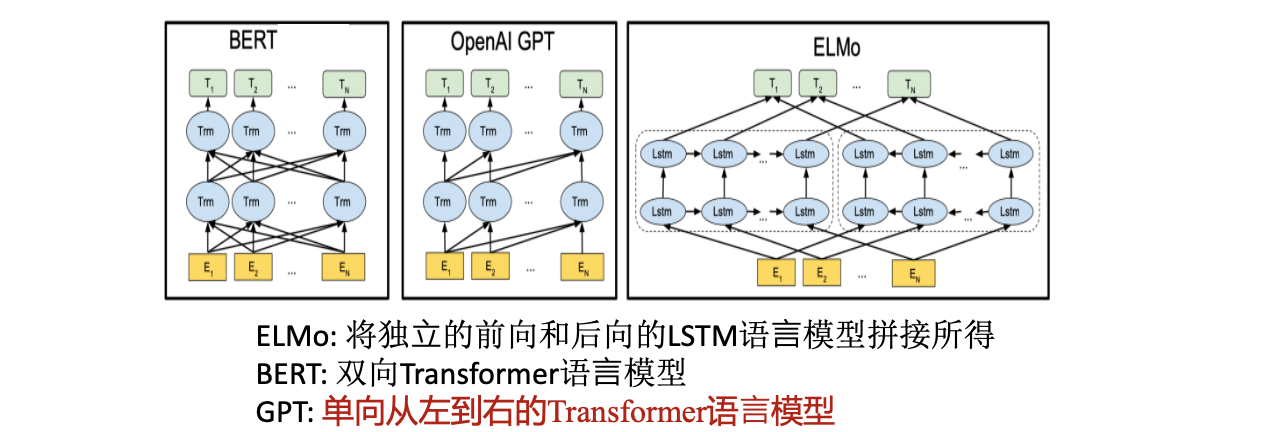
- Elmo: Embeddings from Language Models,首次使用大规模语料训练一个两层双向的RNN。
- Bert: Bidirectional Encoder Representations from Transformers, transformer结构的encoder。
- GPT: Generative Pre-Training,transformer结构的decoder。
- In-context learning, CoT, few-shot learning, SFT, RLHF。由于对llm 部分比较了解,此处省略。
四. 讨论:预训练语言模型能否作为世界模型

相关论文:
Language Models Represent Space and Time, ICLR2024, MIT.
Reasoning with Language Model is Planning with World Model, EMNLP 2023, US San Diego.
Language Models Meet World Models, AAAI 2024, UC San Diego
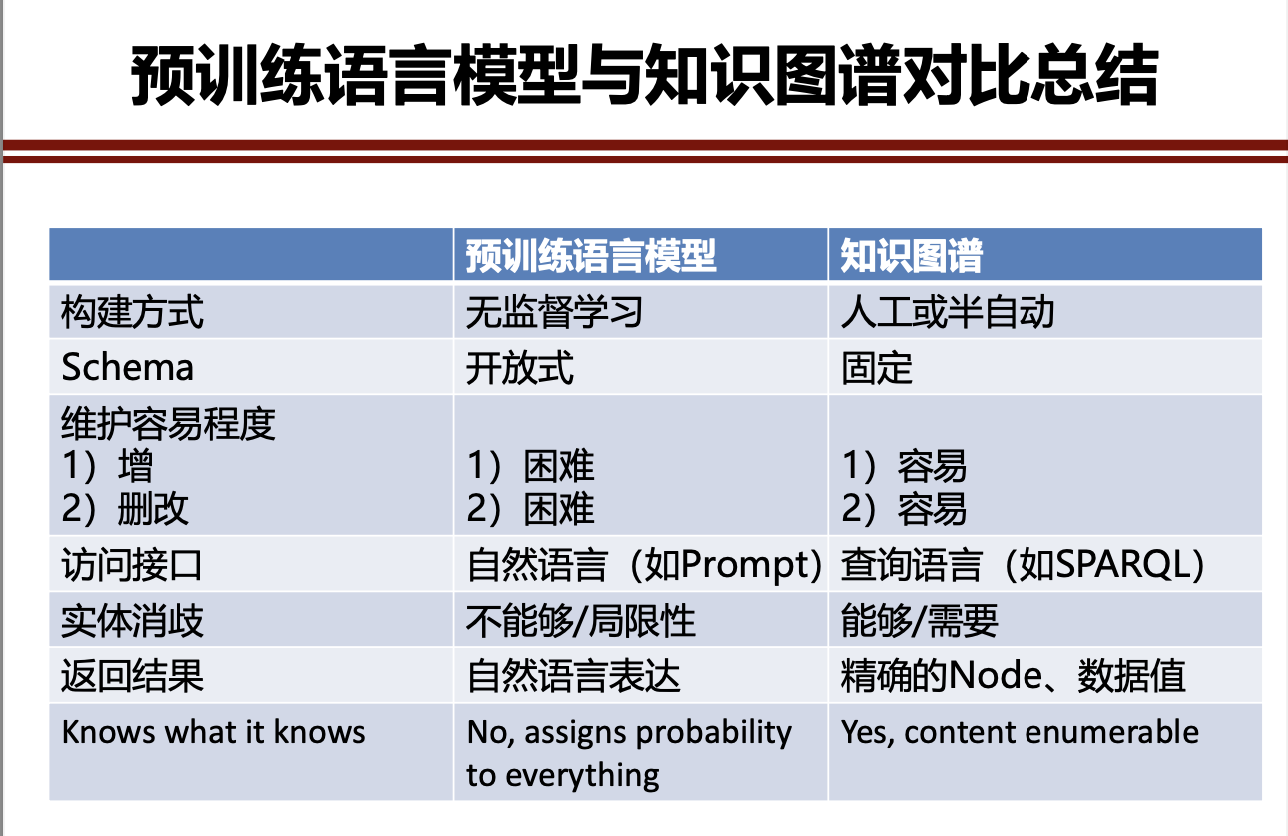
五. 讨论:预训练语言模型能否作为知识库
六. 参考文献
中国科学院大学赵军老师 知识工程 课程课件
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.