
Bayesian Optimization
超参数优化算法。通过构建一个代理模型(通常是高斯过程,GP)来近似目标函数,并使用该模型的预测和不确定性信息来决定下一次评估目标函数的最优位置。实际上是优化对目标函数的估计,属于序贯模型优化(SMBO)的一种。
SMBO:一类用于优化复杂、黑箱函数的策略,它通过构建代理模型来模拟目标函数,并通过不断更新模型来引导下一步的采样。
1. 基本原理
基本步骤:
- 初始样本选择:首先通过随机或空间填充方法选择一些样本点,评估这些点的目标函数值f(x)。
- 代理模型构建:基于已有的样本点,利用高斯过程构建目标函数的代理模型。高斯过程不仅可以预测目标函数的值,还能提供该预测的置信区间。
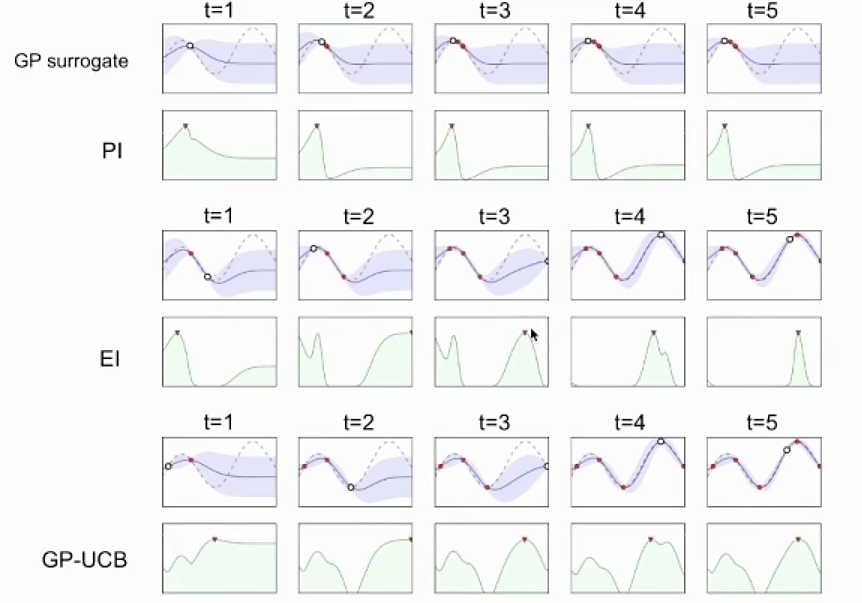
- 采集函数选择:贝叶斯优化使用采集函数来决定下一个需要评估的点。采集函数平衡了探索(在高不确定性区域探索可能的最优点)和利用(在已知较优区域集中评估)。
- 目标函数评估:根据采集函数选择的下一个点,评估目标函数,并将结果纳入已有样本集。
- 模型更新:更新高斯过程模型,以包括新的采样点。
- 重复迭代:不断重复步骤3-5,直到满足停止条件(例如达到设定的评估次数或优化精度)。
注意:在超参数优化过程中,需要定义的f(x)一半是交叉验证/损失函数的结果,我们清楚损失函数的表达式,但是不了解损失函数的内在规律(如单调性,最小值等),因此在超参数优化中的f(x)不能算是严格意义上的黑盒函数。
采集函数:(第3步)基于最小值出现频率确定下一个观测点。
- 概率增量PI,Probability of improvement,希望下一个点的函数值比经验中最大的函数值多一个微小增量\(\epsilon\)的概率最大。过于关注探索
- 期望增量EI,Expectation improvement,希望下一个点的函数值离全局最优值的距离最近。
- 置信度上界,Upper Confidence Bound,通过平衡利用(即选择预测均值高的点)和探索(即选择预测不确定性大的点)来引导优化过程。通过选择置信区间的上界最大的点,既能够确保在当前已有信息下的最优解(即利用已有数据),又能够鼓励对不确定区域的探索(因为标准差较大的点具有更大的潜在提升空间)。
- 信息熵,Entropy,希望熵在全局最优点上下降的最多,减少不确定性。
2. 参考资料
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.