
Unifying Large Language Models and Knowledge Graphs: A Roadmap
类型:文献综述
第一作者:Shirui Pan
作者单位:Griffith University
发表时间:2024/07
发表期刊:IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING
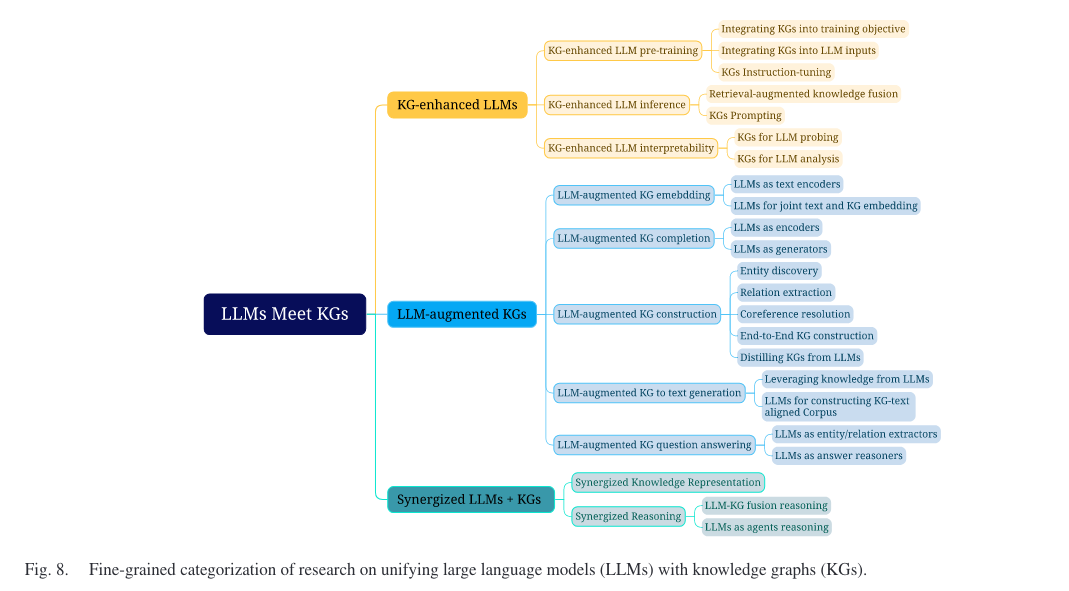
键内容:对 KG-enhanced LLMs, LLM-augmented KGs, Synergized LLMs + KGs 三种框架进行介绍
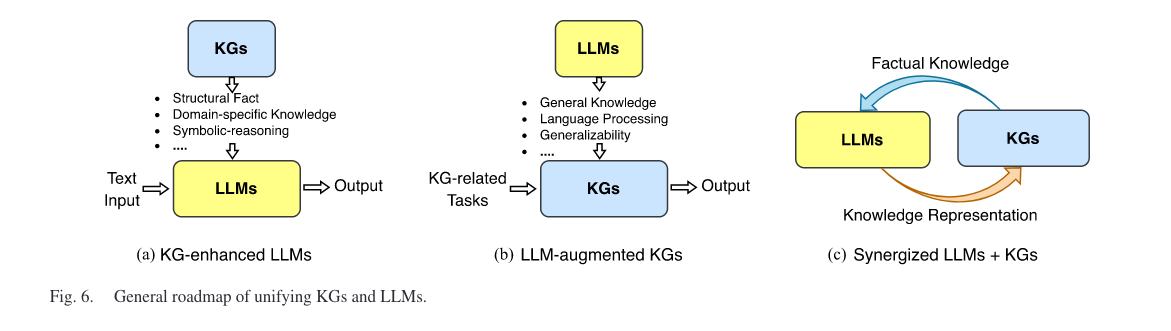
1. background
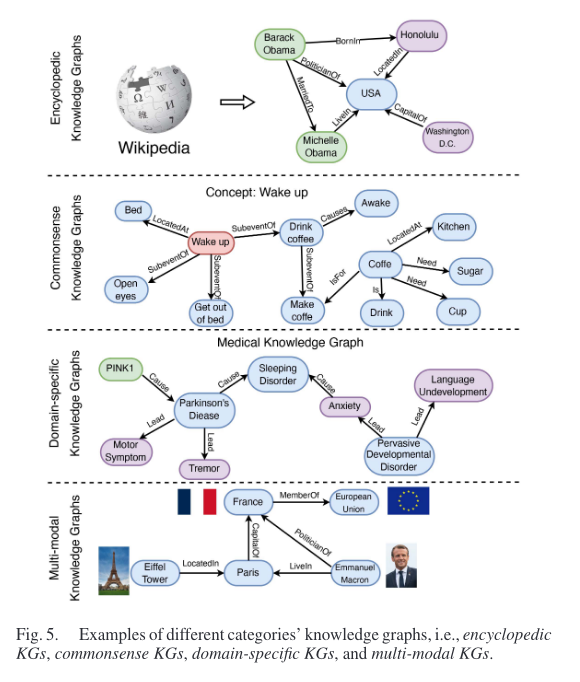
KGs的四种分类:百科全书式知识图谱、常识知识图谱、特定领域知识图谱和多模态知识图谱。
LLM 与 KGs 的优缺点对比:
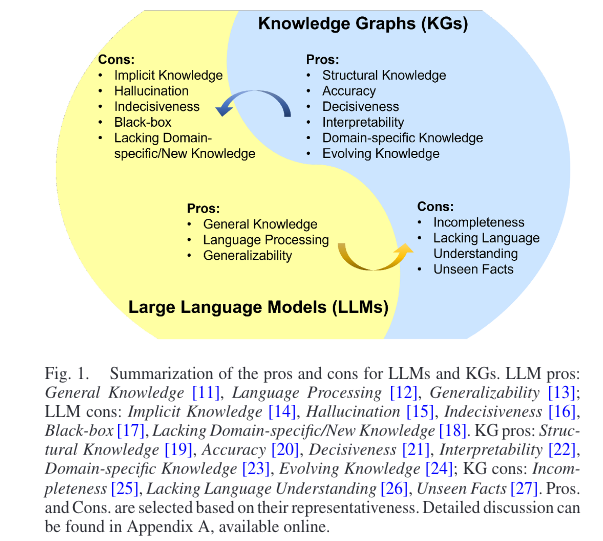
其中,KGs 的缺点 Unseen Facts:知识图谱无法有效地对看不见的实体进行建模并表示新的事实知识。此外,知识图谱中丰富的文本信息常被忽略。
LLM 与 KGs 的应用示例:
2. KG-enhanced LLMs
2.1 KG-Enhanced LLM Pre-Training
2.1.1 Integrating KGs into training objective
两种方式:
- 在预训练中暴露更多的实体,通过改变词语的掩码概率实现。如GLM中,假定在知识图谱中一定跳数内可以到达的实体是较为重要的实体,并且在预训练期间会给予它们更高的掩码概率。而在SKEP中,通过词语的情感分配不同的掩码概率。
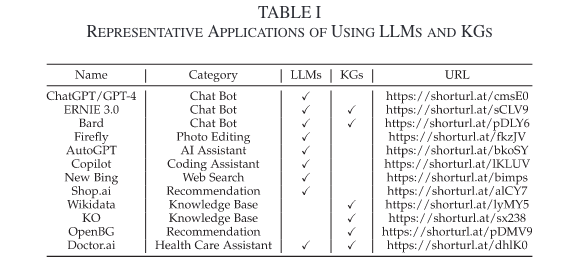
- 更改训练训练的目标函数。如对ERNIE,目标为tokens到entity的对齐链接,如下图所示。对WKLM,首先用其他相同类型的实体替换文本中的实体,然后将它们输入 LLM,训练目标为区分实体是否已被替换。
2.1.2 Integrating KGs into LLM inputs
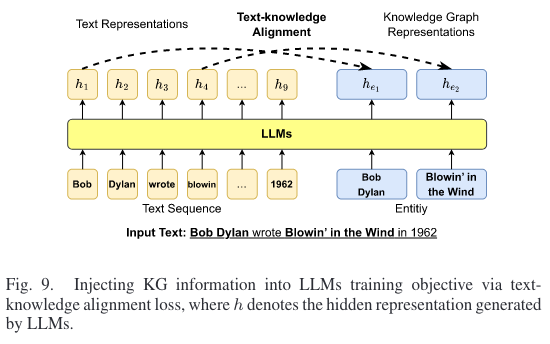
Colake中提出的集成方法如下图所示,需要注意的是:
- 只有句子中的实体才能访问知识图谱中的三元组信息
- 输入句子的 tokens 形成了完全图
- 更多的关注热门实体,而忽视了低频和长尾实体。
2.1.3 KGs Instruction-tuning
KG指令微调的目的不是向LLM注入事实知识,而是让LLM更好的理解KG的结构。具体分析见 KG指令微调部分。
2.2 KG-Enhanced LLM Inference
虽然通过训练确实可以为LLM注入大量的知识,但是这些知识缺乏时效性,且模型训练需要消耗大量资源,因此可以借助KGs 在LLM推理时注入知识。两种方式:
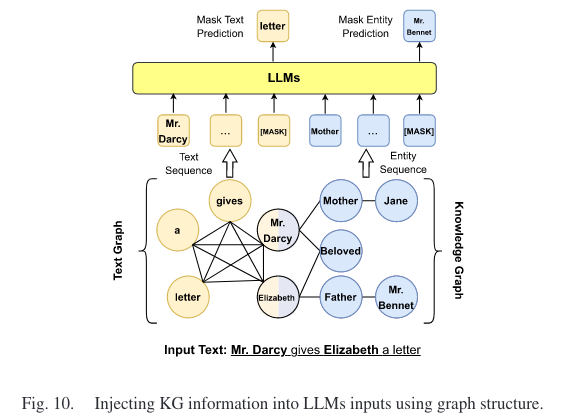
- RAG,Retrieval-Augmented Knowledge Fusion
- KGs Prompting,设计提示,将结构化的知识图谱转换为文本序列,然后将其作为上下文输入到LLM中。但通常设计提示需要耗费大量人力。
2.3 KG-Enhanced LLM Interpretability
LLM 可解释性是指对其内部工作和决策过程的理解和解释。研究人员试图利用知识图谱来提高LLM的可解释性,大致可以分为两类:1)用于语言模型探测的知识图谱,2)用于语言模型分析的知识图谱。
KGs for LLM Probing,旨在理解 LLM 中存储的知识
下图为LAMA 使用 KGs 对 LLM 进行知识探测的示例图,首先通过预定义的提示模板将 KG 中的事实转换为完形填空语句,然后使用 LLM 来预测缺失的实体。预测结果用于评估 LLM 中存储的知识。
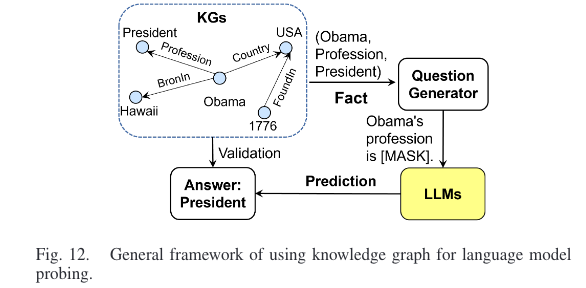
注意:可以通过优化提示来更准确的评估 LLM 中包含的知识,且研究发现 LLM 对低频/尾部事实知识的掌握较差。
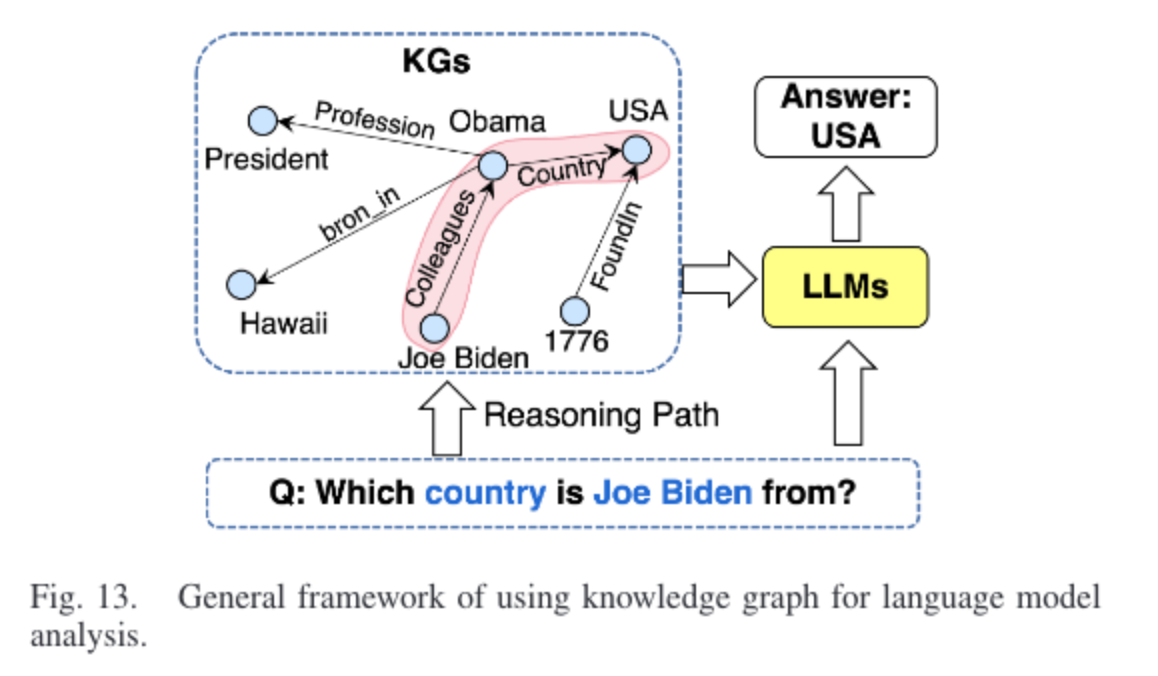
KGs for LLM Analysis,旨在分析 LLM 中的推理过程,如 LLM 如何生成结果,LLM 的功能和结构如何工作等。
一种方式是将 LLM 在每个推理步骤中生成的结果都以知识图谱为基础。这样,LLM的推理过程就可以通过从KG中提取图结构来解释,如下所示。
3. LLM-AUGMENTED KGS
3.1 LLM-Augmented KG Embedding
知识图嵌入(KGE)旨在将每个实体和关系映射到低维向量空间,这些嵌入包含知识图谱的语义和结构信息。通常有两种方式:1)采用 LLM 通过对实体和关系的文本描述进行编码来丰富KG的表示,2)使用 LLM 将图结构和文本信息同时合并到嵌入空间中。
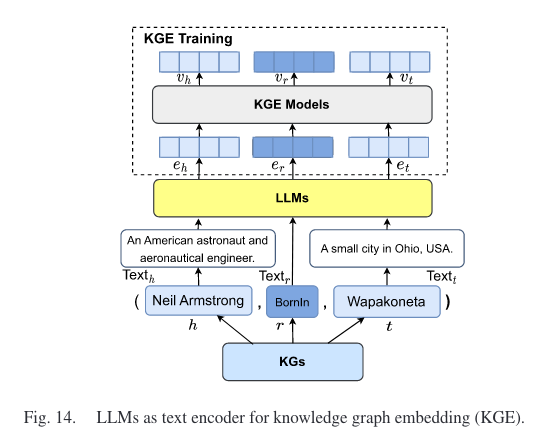
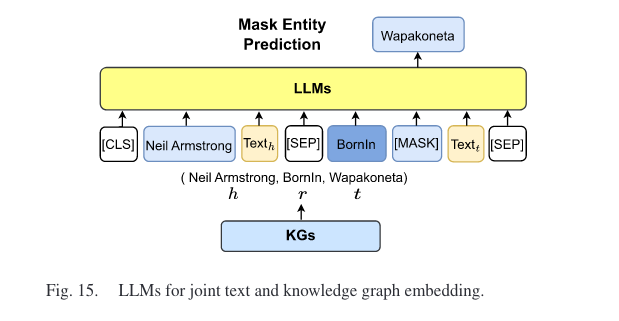
3.2 LLM-Augmented KG Completion
知识图补全(KGC)旨在推断给定知识图谱中缺失的事实。与KGE类似,传统的KGC方法主要关注KG的结构,而没有考虑广泛的文本信息。然而,LLM 的集成使 KGC 方法能够编码文本或生成事实,以获得更好的 KGC 性能。这些方法根据其使用方式分为两个不同的类别:1)LLM 作为编码器(PaE),2)LLM 作为生成器(PaG)。顾名思义,将 LLM 分别作为 encoder, decoder。
LLM as Encoders (PaE)
优点:
- 易于微调,在LLM基础上加上一个预测层,训练时可以冻结LLMs,只需优化预测头
- 输出可整合,预测输出易于与现有的KGC功能整合,用于不同的KGC任务
缺点
- 计算开销大,推理阶段需要为每个候选实体计算分数,计算昂贵
- 不能泛化到未见过的实体
- 需要LLMs的表示输出,但无法获取闭源LLM 的表示输出
LLM as Generators (PaG)
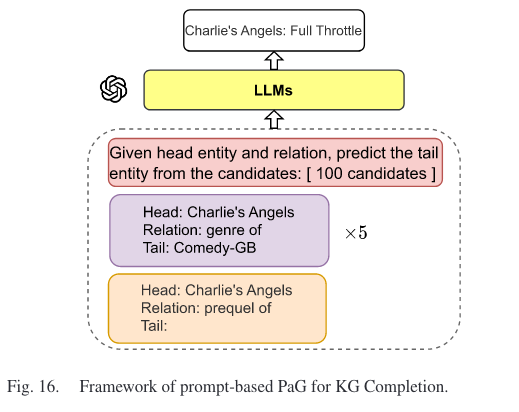
优点:无需微调,能泛化到未见过的实体
缺点:生成的实体可能不在KGs 中,设计有效的提示需要耗费大量人力
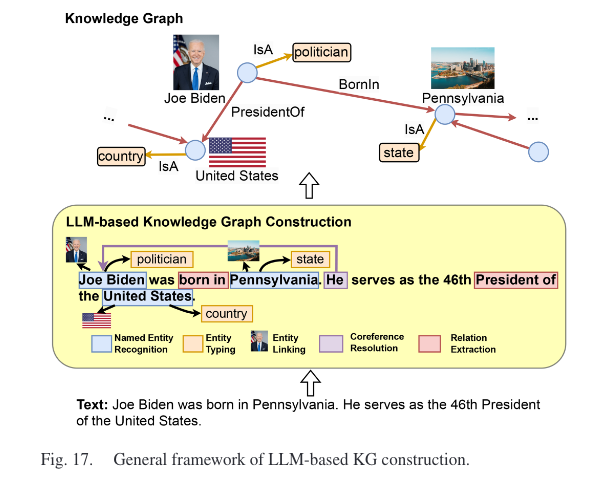
3.3 LLM-Augmented KG Construction
知识图谱构建通常包含以下几个步骤:实体抽取,共指消解,关系抽取。
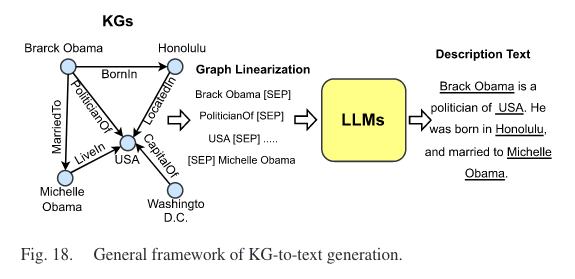
3.4 LLM-Augmented KG-to-Text Generation
旨在生成准确一致地描述输入知识图谱信息的高质量文本,但收集大量图文并行数据具有挑战性且成本高昂,导致训练不足和生成质量差。有两种方法:1)利用 LLM 的知识,如下图所示,线性遍历知识图谱作为输入,用 LLM 获取文本输出,但存在问题是 LLM 的无监督预训练目标不一定与知识图谱到文本生成的任务很好地契合,2)构建大规模弱监督知识图谱文本语料库。
3.5 LLM-Augmented KG Question Answering
知识图谱问答(KGQA)旨在根据知识图谱中存储的结构化事实找到自然语言问题的答案。可以将LLM作为实体/关系的抽取器,或是答案推理器,即根据检索到的事实进行推理。
4. SYNERGIZED LLMS +KGS
主要可以分为协同知识表示,协同推理两部分。
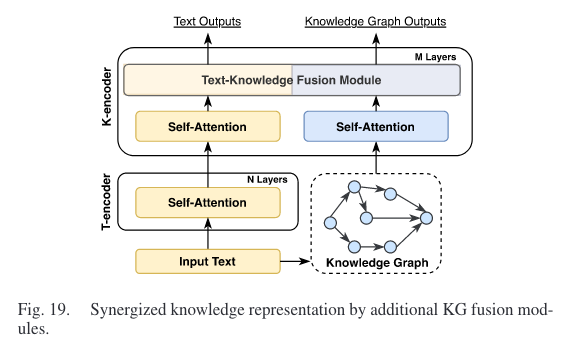
4.1 Synergized Knowledge Representation
文本语料库和知识图谱都蕴藏着海量的知识。然而,文本语料库中的知识通常是隐式的、非结构化的,而知识图谱中的知识是显性的、结构化的。协同知识表示旨在设计一个协同模型,可以有效地表示来自 LLM 和 KG 的知识。协同模型可以更好地理解两个来源的知识,使其对许多下游任务有价值。
4.2 Synergized Reasoning
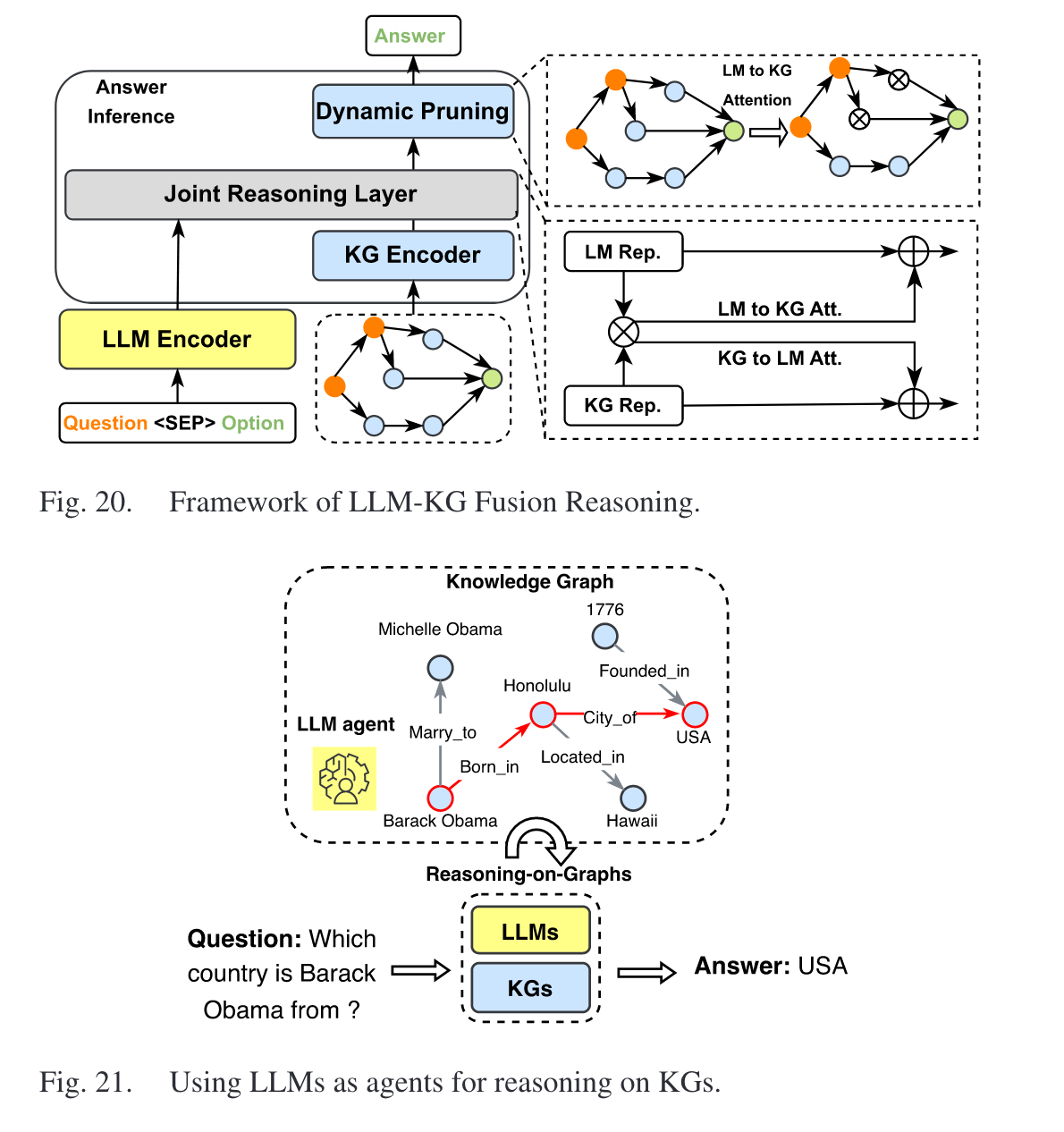
可以分为 LLM-KG 融合推理(使用两个独立的 LLM 和 KG 编码器来处理文本和 KG 输入),LLM 代理推理(使用 LLM 作为与 KG 交互进行推理的 代理)两部分。
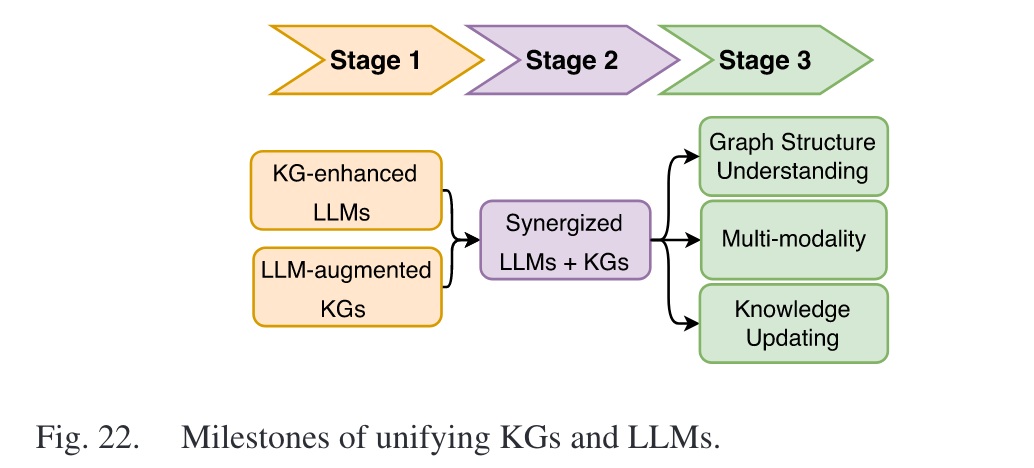
5. FUTURE DIRECTIONS AND MILESTONES
- KGs for Hallucination Detection in LLMs
- KGs for Editing Knowledge in LLMs,尽管 LLM 能够存储海量的现实世界知识,但他们无法随着现实世界情况的变化而快速更新其内部知识。有研究人员提出了一些研究工作来编辑 LLM 的知识,而无需重新训练整个模型。然而,此类解决方案仍然存在性能不佳或计算开销过大的问题。现有研究还表明,编辑单个事实会对其他相关知识产生连锁反应。因此,有必要开发一种更高效、更有效的方法来编辑 LLM 知识。最近,研究人员尝试利用知识图谱来有效地编辑 LLM 的知识。
- KGs for Black-Box LLMs Knowledge Injection
- Multi-Modal LLMs for KGs
- LLMs for Understanding KG Structure,基于纯文本数据训练的 LLM 并非旨在理解知识图等结构化数据。因此, LLM 可能无法完全掌握或理解知识图谱结构传达的信息。一种直接的方法是将结构化数据线性化为 LLM 可以理解的句子。然而,知识图谱的规模使得不可能将整个知识图谱线性化为输入。此外,线性化过程可能会丢失知识图谱中的一些底层信息。因此,有必要开发能够直接理解KG结构并对其进行推理的LLM。
- Synergized LLMs and KGs for Birectional Reasoning
6. CONCLUSION
7. 参考论文
Pan S, Luo L, Wang Y, et al. Unifying large language models and knowledge graphs: A roadmap[J]. IEEE Transactions on Knowledge and Data Engineering, 2024.