
Knowledge Prompting in Pre-trained Language Model for Natural Language Understanding
第一作者:Jianing Wang
作者单位:华东师范大学
发表时间:2022/10
发表期刊:EMNLP2022
关键内容:提出了一种基于知识提示的 PLM 架构:KP-PLM。首先根据每个句子上下文的知识库构建一个知识子图,再设计多个连续提示规则,将知识子图转化为自然语言提示,对模型进行微调。并提出了两个知识感知的自监督任务:prompt relevance inspection and masked prompt modeling。前者旨在让PLM 学习多个知识提示的语义相关性,后者预测 prompt 中的屏蔽实体。
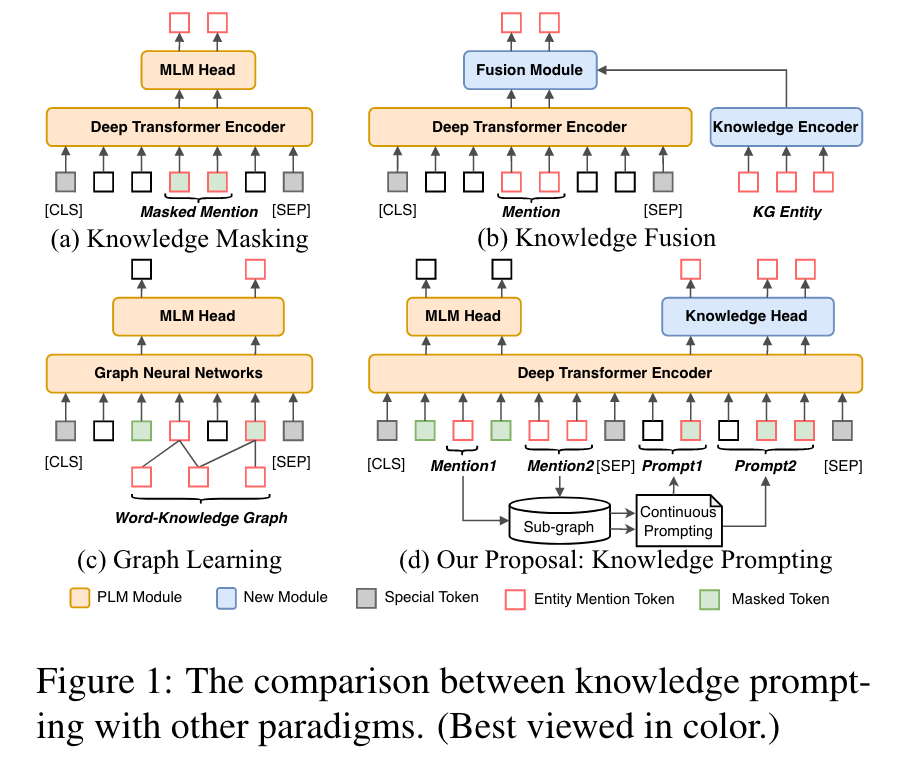
1. 引言
增强PLM知识的方法有以下几种:
- knowledge-masking-based methods
- knowledge-fusion-based methods
- graph-learning-based methods
但是这些方法存在以下不足:
- 一些方法通过堆叠复杂的模块来修改现有PLM的内部结构,增加了模型的计算成本
- 一些方法从知识库中引入冗余和不相关的知识(知识噪声),可能会降低模型的性能
因此,作者提出了一种基于知识提示的 PLM 架构:KP-PLM,可以有效的解决以上两个不足,如图1、图2所示。
2.KP-PLM 模型框架
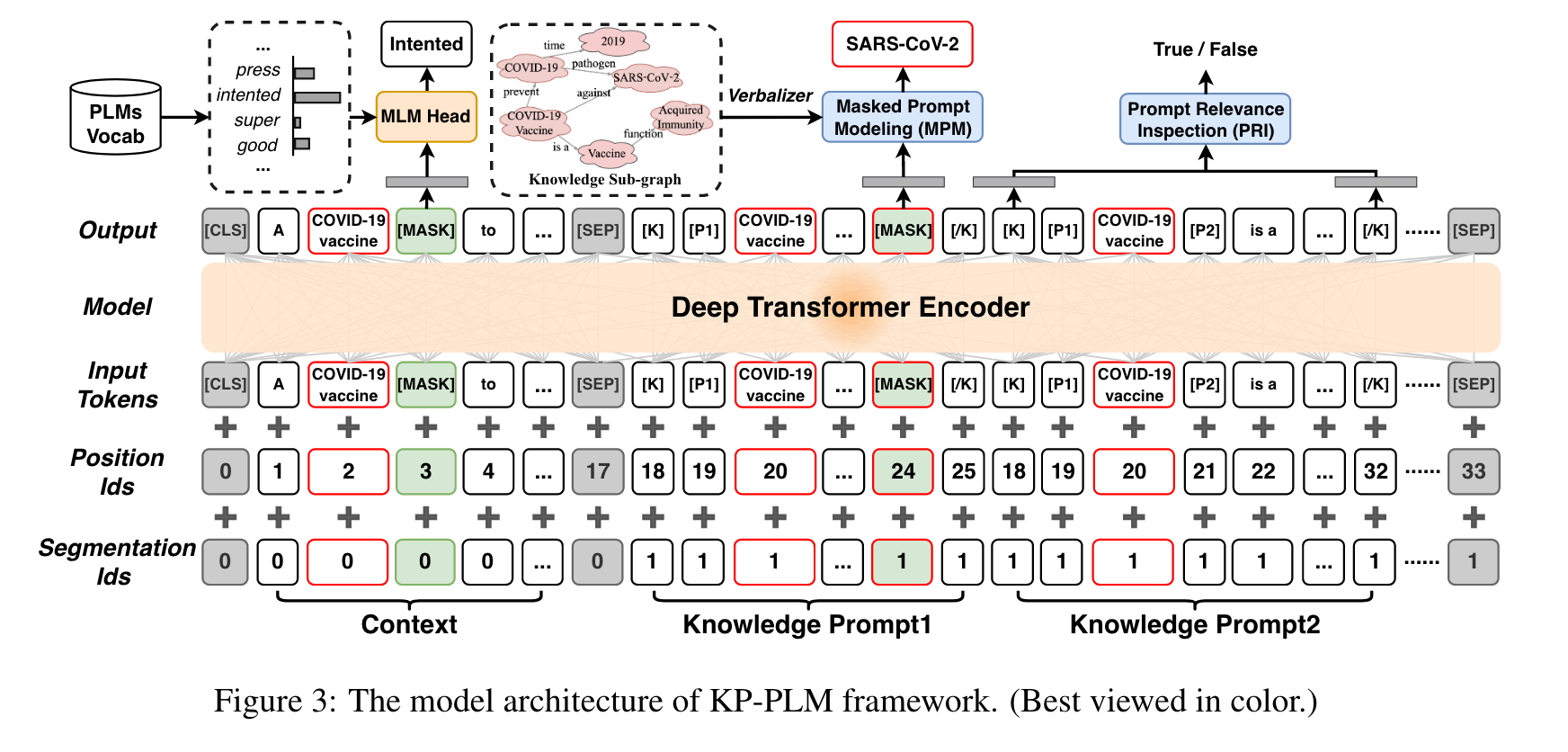
2.1 Knowledge Prompting
知识提示旨在为每个句子构建知识子图,然后将事实知识转化为自然语言提示。下图分两个步骤说明了该过程。
- 上下文知识子图构建。从每个句子中抽取中所有的实体,选择主题实体,根据该主题实体构建一个2-hop子图,再对该子图进行pruning。pruning规则:若尾实体未出现在该句子的抽取实体集合中,删除该路径。
- Continuous prompting mapping.根据子图中的一阶和二阶结构信息设计了三种类型的提示映射规则。其中,[K]、[/K]为知识触发标记,[Pi]为伪标记。

2.2 Model Architecture
主要是对 Input Embedding Layer 进行介绍。嵌入分为 token embeddings, position embeddings and segmentation embeddings 三种类型。
- token embeddings,the trigger and pseudo tokens are randomly initialized while others are initialized by looking up the PLM embedding table.
- position embeddings,为了减轻 prompt 顺序对模型性能的影响,所有 prompt 的起始位置编码相同
- segmentation embeddings,同样的,对所有 prompt 使用相同的分段 id,并为其起始标记设置相同的位置 id。
2.3 Self-supervised Pre-training Tasks
- Prompt Relevance Inspection (PRI),由于提示可以将事实知识注入 PLM,因此它们应该在语义上与上下文序列相关。因此,作者设计了一种提示相关性检查任务,增强了模型学习提示与句子相关性的能力。对于训练语料库中的每个句子 S,生成一组相关提示集 PS。并构造一个“正”提示集 Pos。 此外,对于每个句子 S,可以从 PS 中随机选择一个提示,并从该提示中随机选择一个实体,替换为 KB 中的任意实体。最后将更新的提示标记为否定提示,并添加到“负”提示集 Neg。利用这两个提示集进行训练。
- Masked Prompt Modeling (MPM). 与传统的实体预测相比,有两点不同:一是搜索空间不同(不是在整个 PLM 词汇库上进行搜索,而是在上下文知识子图中进行搜索),二是训练数据集的构建(给定一个训练语料库,对于每个句子 S,生成一组相关提示集 PS,在任意选择的提示 P ∈ PS 中使用 [MASK] 标记随机屏蔽实体(主题实体除外),构成训练集用于模型训练)
3. 实验
- 基座模型:RoBERTa-base
- 数据集:使用的知识库是WikiData5M,其中包括3,085,345个实体和822个关系类型。
- 对比PLM选择:ERNIE-THU, KnowBERT, KEPLER, CoLAKE, K-Adapter, DKPLM。
- 实验设置:Knowledge-aware Tasks(使用实体类型预测、关系提取和知识探测三个任务来评估模型性能),Performance on General NLU Tasks,Knowledge Prompting Study,Ablation Study
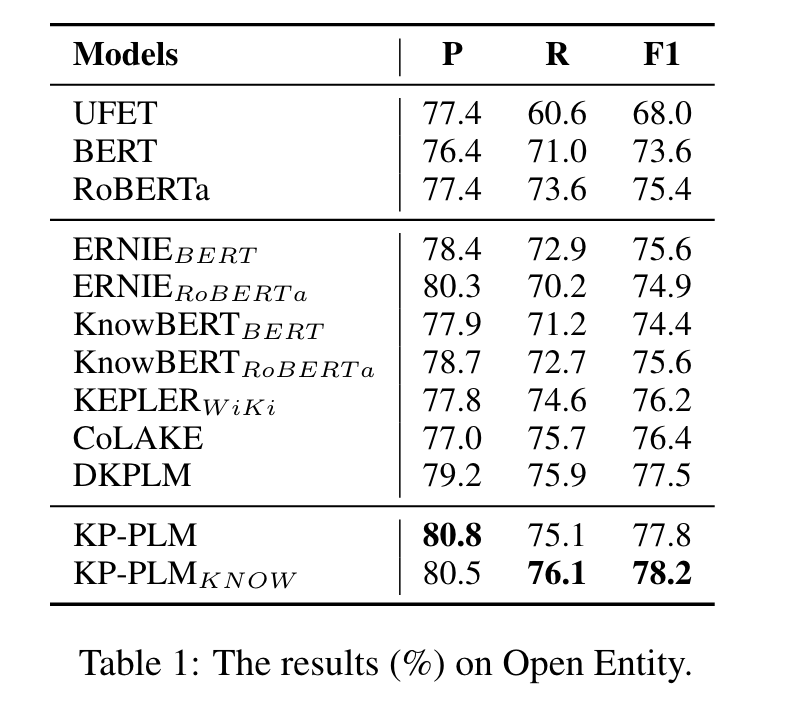
3.1 实验结果
-
知识感知–实体类型预测,根据给定一个句子和相应的实体提及,预测实体的类型。模型变体 KP-PLMKNOW ,它通过直接将知识提示与每个示例连接起来,在微调阶段使用知识提示。
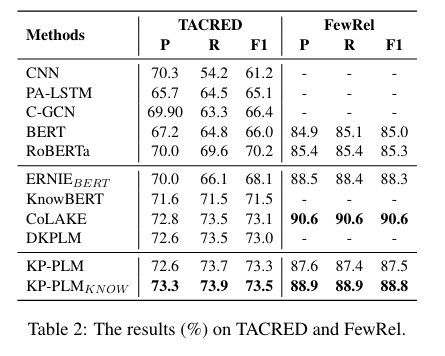
-
知识感知–关系抽取,根据相应的文本对两个给定实体之间的关系进行分类。
-
知识感知–知识探测,旨在评估 PLM 是否拥有零样本环境下的内在事实知识。
-
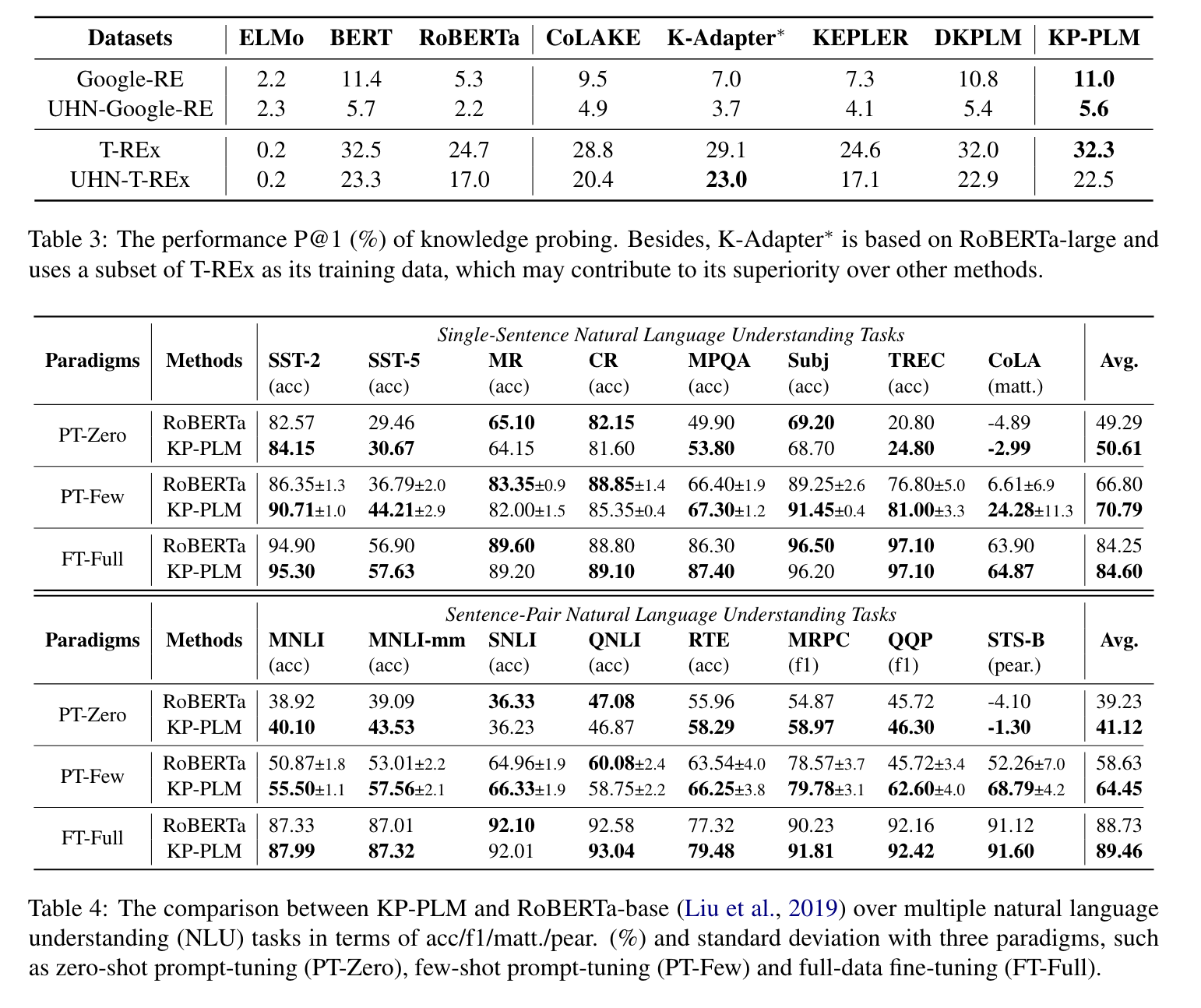
Performance on General NLU Tasks,KP-PLM 与 RoBERTa-base 在多个自然理解任务中的对比,
-
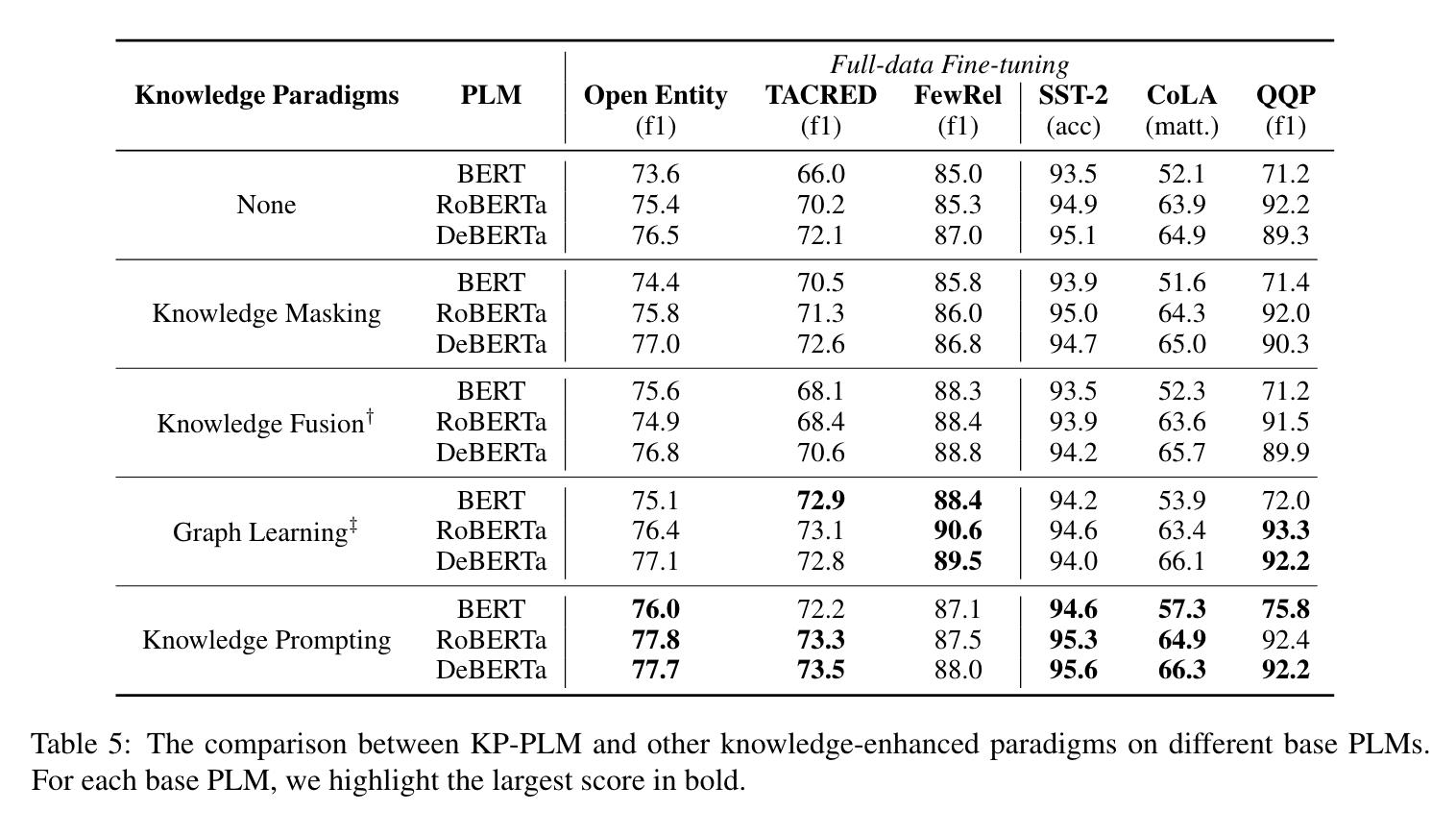
不同知识增强PLM 架构的对比
-
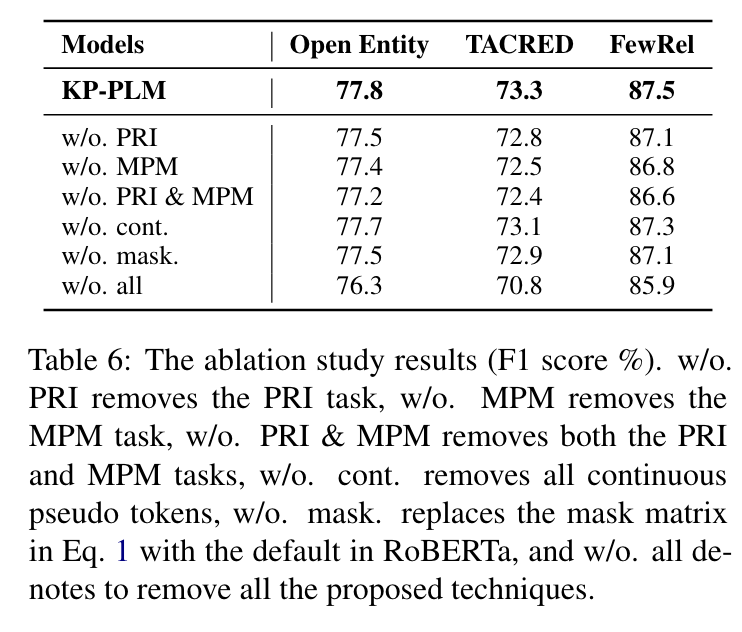
消融实验
4.结论
In this paper, we presented a seminal knowledge prompting paradigm, based on which a novel knowledge-prompting-based PLM framework KPPLM was proposed. Experimental results validate the effectiveness of knowledge prompting in boosting the performance of PLMs.
5.参考文献
Wang J, Huang W, Shi Q, et al. Knowledge prompting in pre-trained language model for natural language understanding[J]. arXiv preprint arXiv:2210.08536, 2022.