
Ontology-enhanced Prompt-tuning for Few-shot Learning
第一作者:Hongbin Ye, Ningyu Zhang
作者单位:浙江大学
发表时间:2022/4
发表期刊:Proceedings of the ACM Web Conference 2022
关键内容:探索如何更好的使用预训练语言模型进行 few-shot learning 知识注入,并提出本体增强提示调优(OntoPrompt)。如何优化:将KG的本体知识转化为文本用于模型训练,并修改注意力机制以减小知识噪声,最后,对本体嵌入向量也进行参数训练。
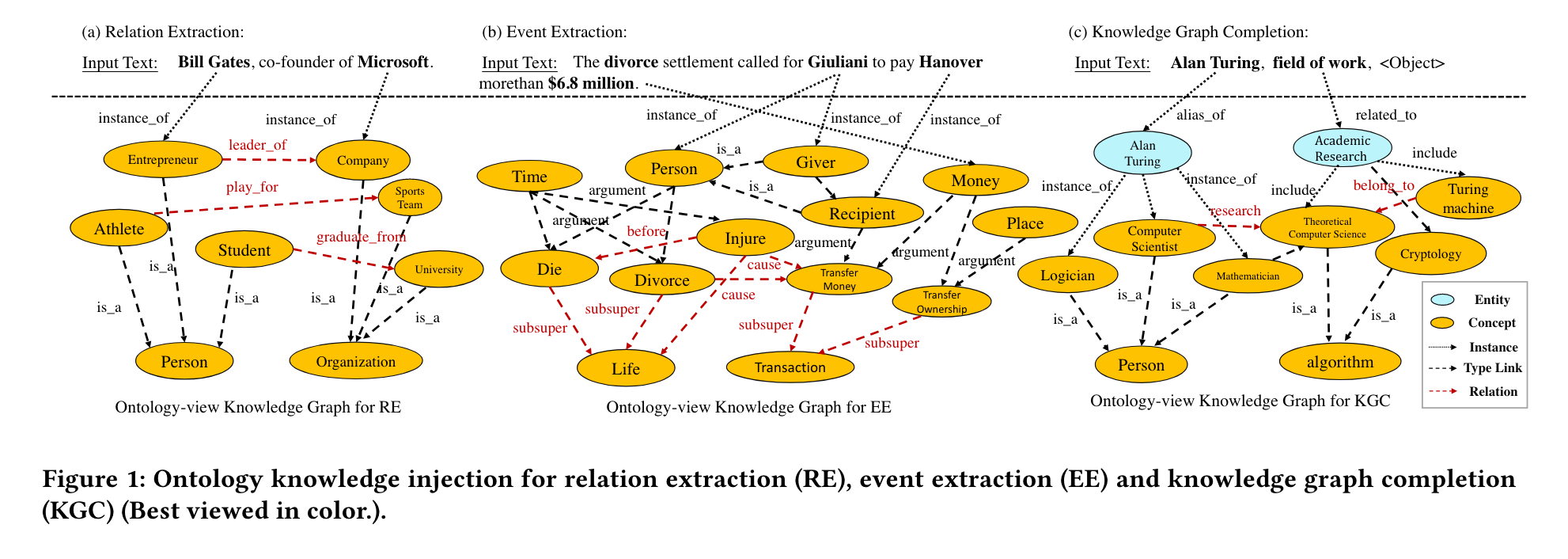
1. INTRODUCTION
few-shot learning 中存在的三个问题:
- 知识缺失。由于外部知识库的不完整性,可能无法检索与任务相关的事实,从而无法为下游任务提供有用的信息。
- 知识噪声。先前的研究已经证明,并非所有的知识都对下游任务有益,不加区别地注入知识可能会导致负面的知识注入,从而不利于下游任务的性能。
- 知识异质性。下游任务的语言语料库与注入的知识有很大不同,导致两种独立的向量表示,即注入知识不能很好的泛化到下游任务中。
针对这三个问题,作者提出了对应的解决方案:
- 利用预定义的模板将基于外部知识图谱的本体知识转换为文本作为提示。
- 通过跨度敏感的知识注入,来选择信息知识,从而减轻噪声注入。
- 通过集体训练算法来共同优化 下游任务的语言语料库与注入知识 的表示。
最后在关系提取、事件提取和知识图补全这三个任务进行测试,取得了不错的效果。
2. METHODOLOGY
2.1 Ontology Transformation
针对下游任务的差异,对不同的任务利用不同的本体来源进行本体转换。首先从外部知识图中提取每个实例的本体,然后将这些本体转换为原始文本作为辅助提示,如下图所示。
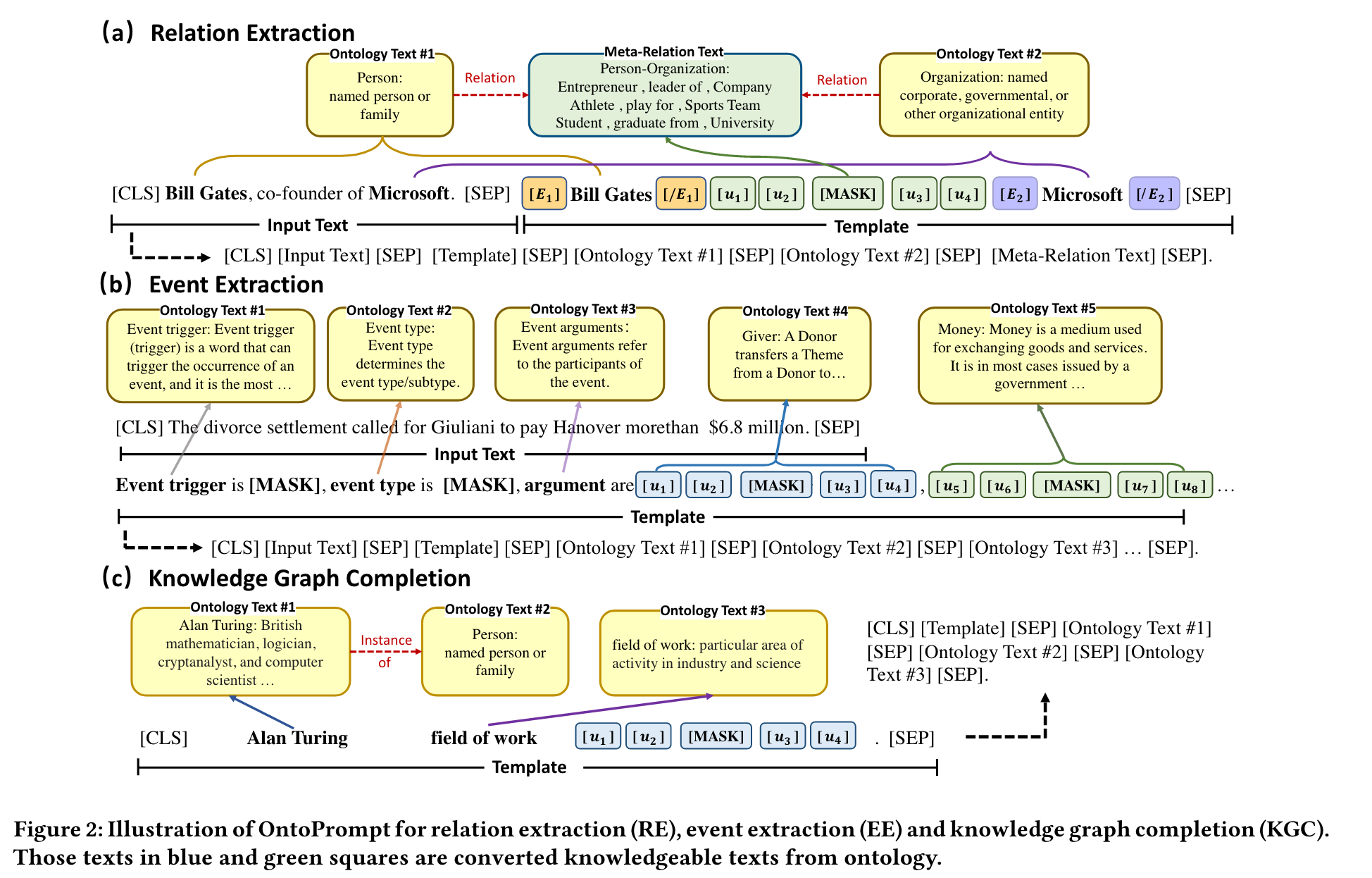
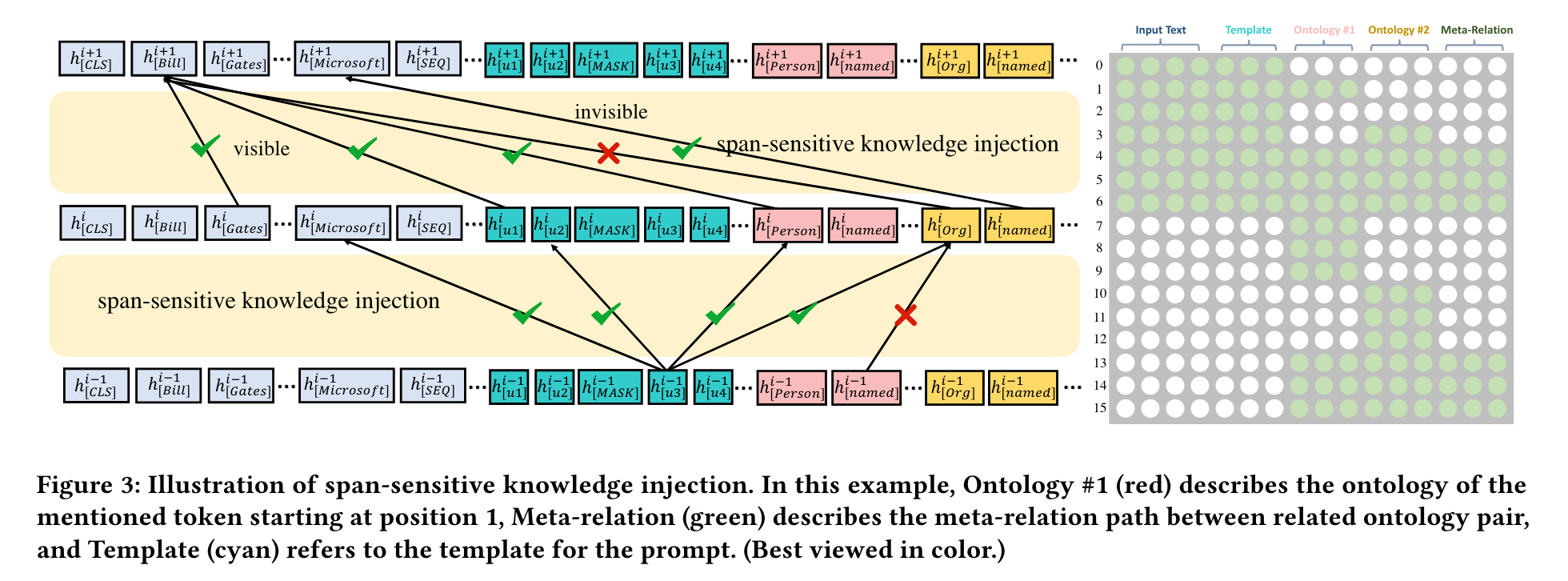
2.2 Span-sensitive Knowledge Injection
给定输入文本 $X_{in} = [x_1, x_2, …, x_L]$ 和 $L$ 个标记,作者使用可视化的矩阵来限制对输入文本的知识注入,即。在语言模型架构中,在softmax层之前添加了具有自注意力权重的注意力掩码矩阵。因此,作者将注意力掩模矩阵M修改如下:
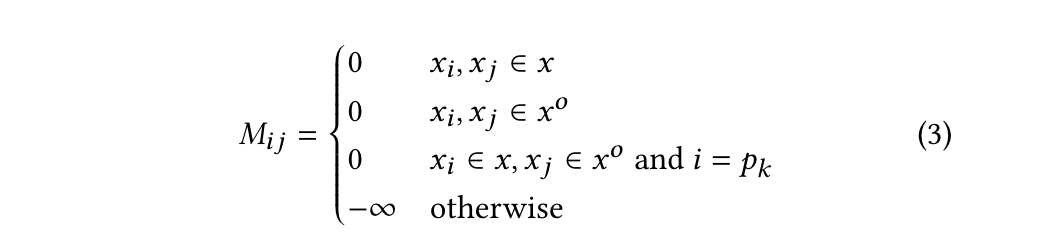
其中,$x$为输入文本,$x^o$为本体文本。当 $M_{ij} = -\infty$ 时,表示$token_i$ 被阻止关注$token_j$,当$M_{ij} = 0$ 时,表示$token_i$ 可以关注$token_j$。$p_k$ 表示输入文本中提到的跨度(例如,关系提取和知识图补全中的实体、触发器或事件提取中的参数)的位置。
2.3 Collective Training
首先,利用真实的词嵌入初始化本体标记,并在固定的语言模型下优化这些本体标记。其次,优化模型的所有参数,包括语言模型和本体标记。
3. EXPERIMENTS
-
数据集
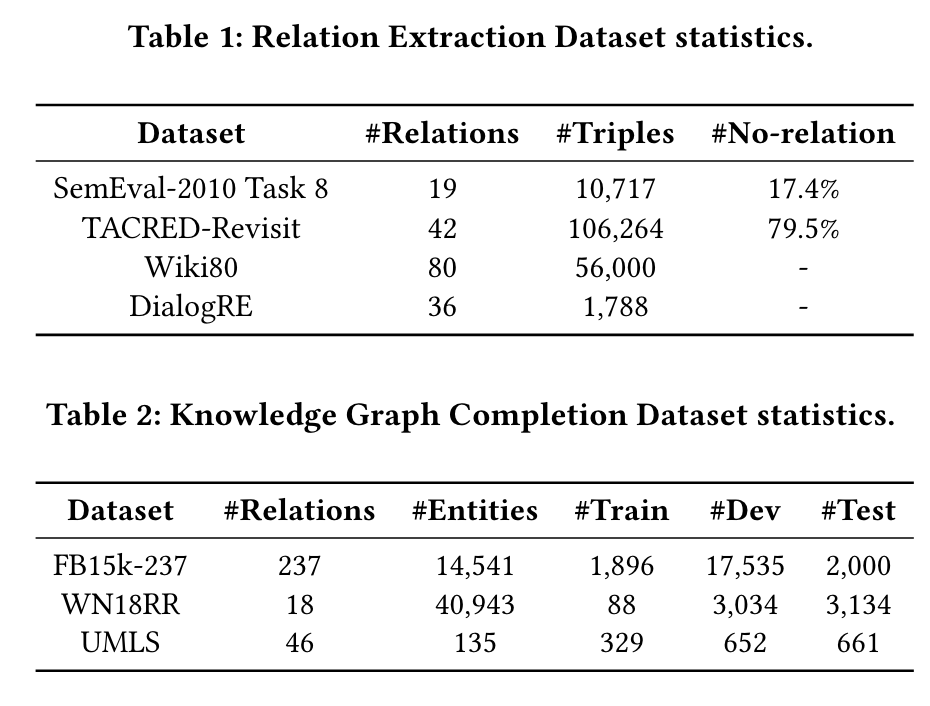
-
关系抽取
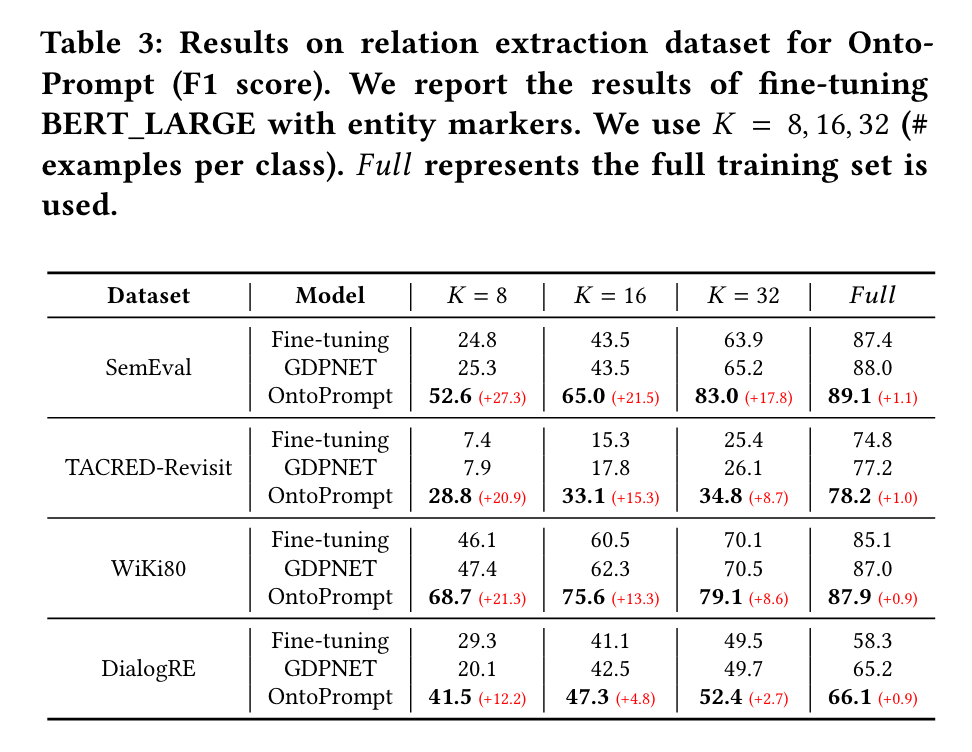
-
知识图谱构建
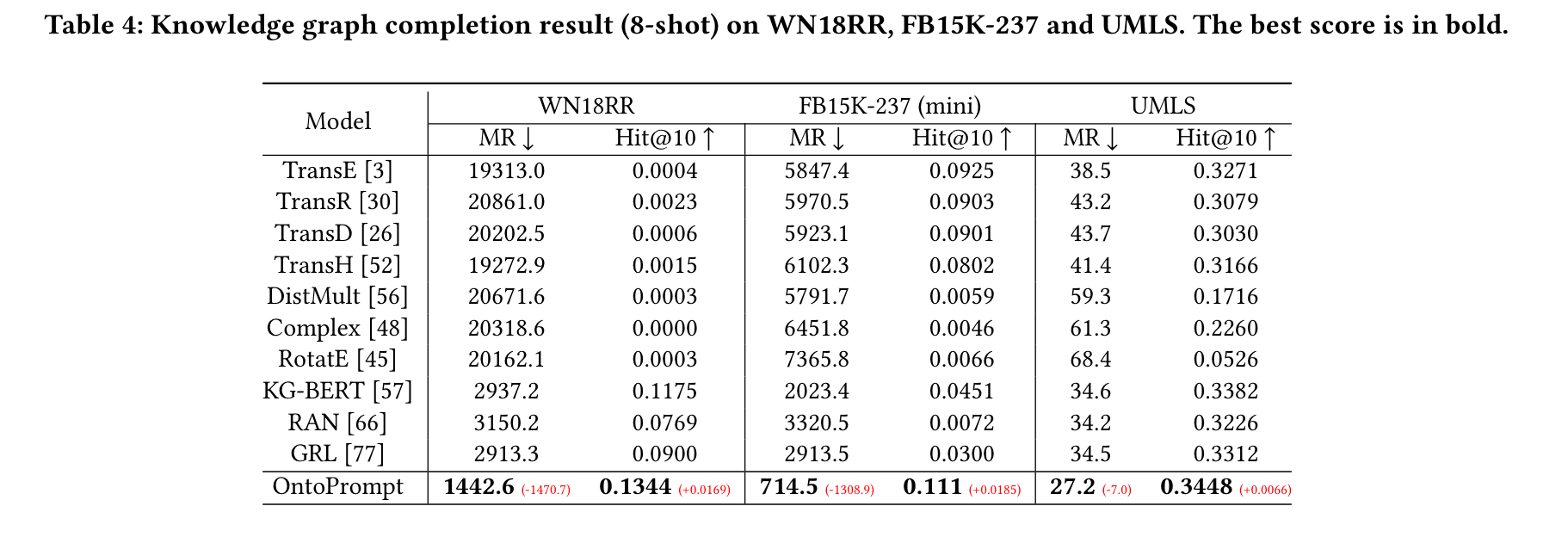
-
事件提取 + 消融实验
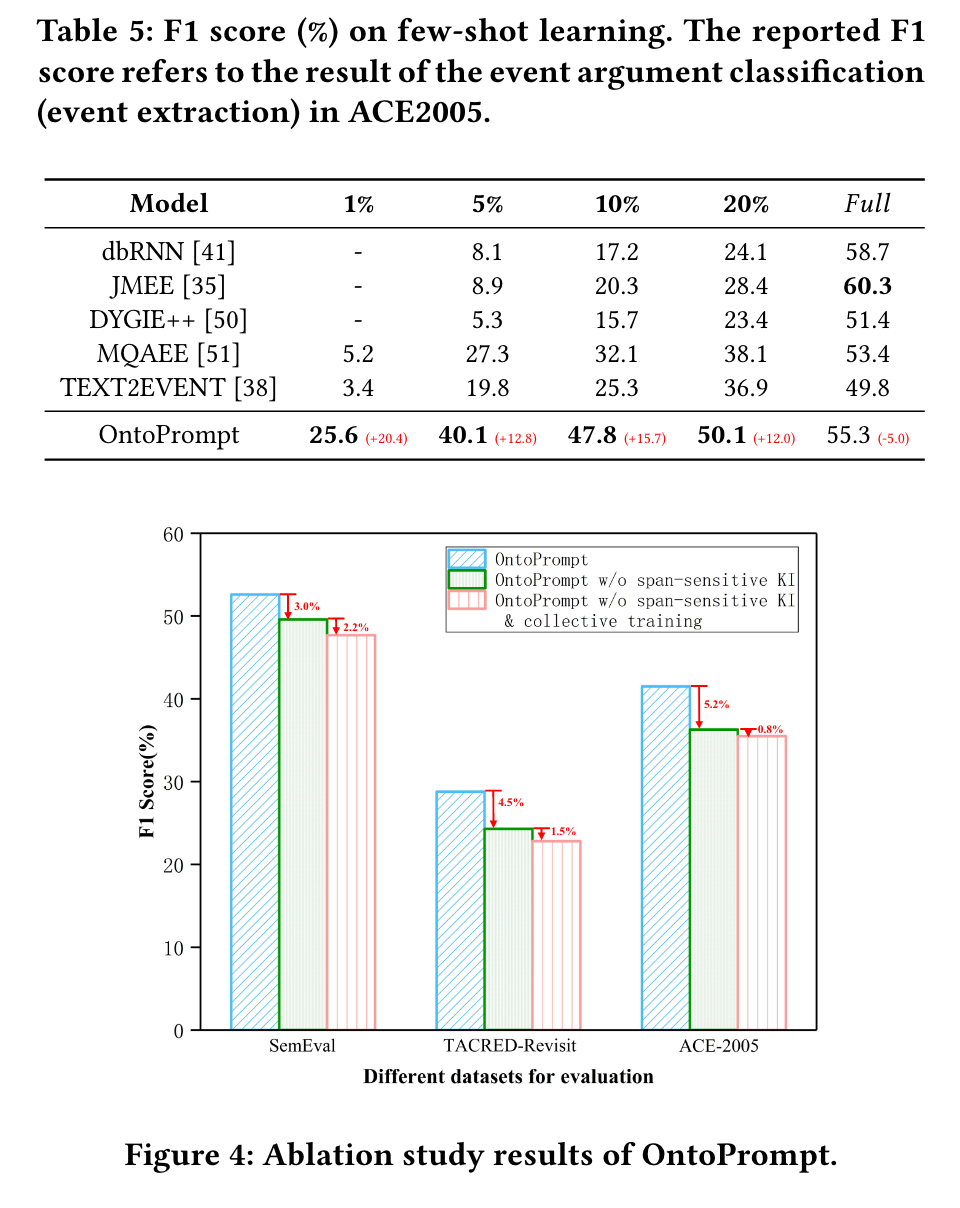
-
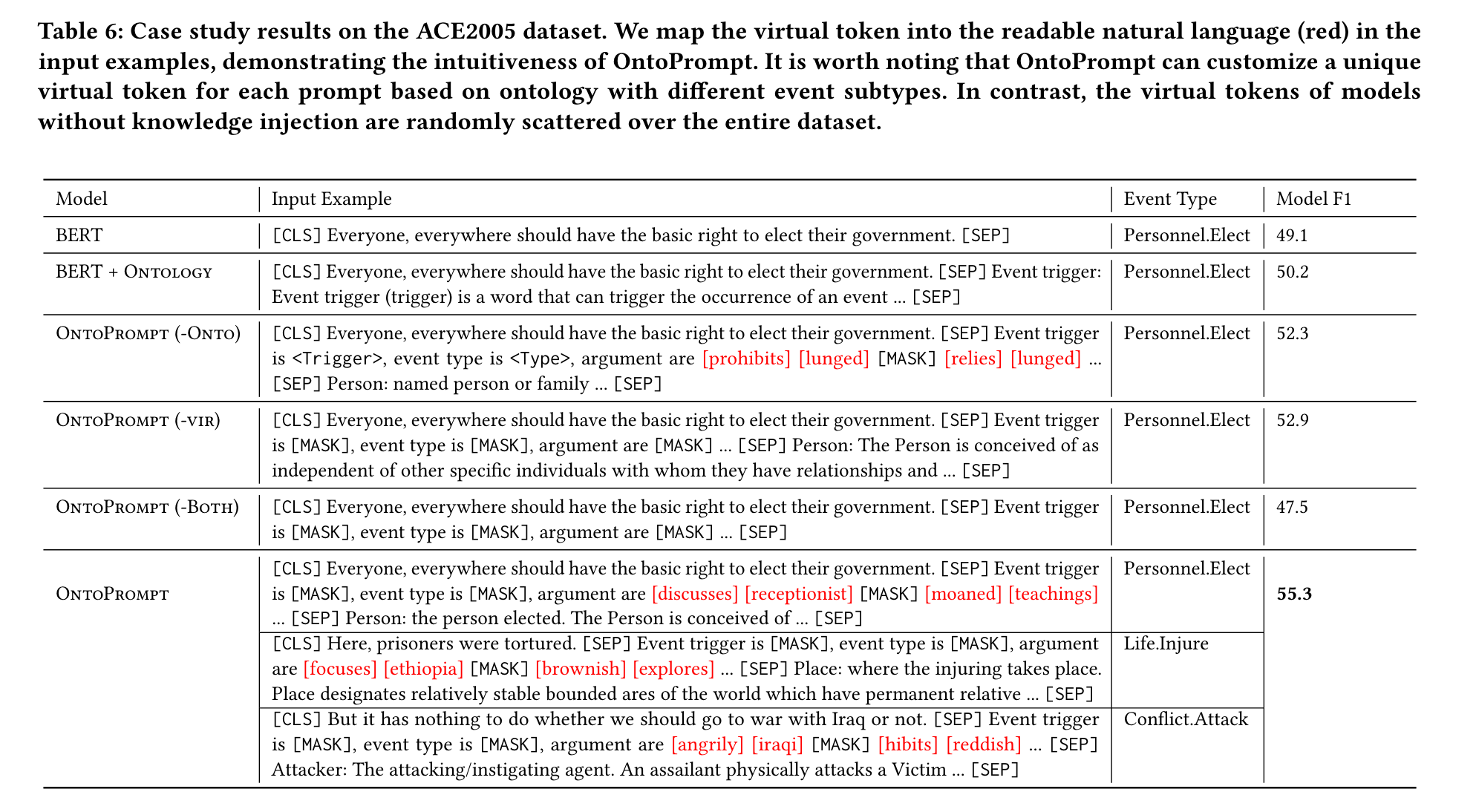
Case Study
4. 参考文献
Ye H, Zhang N, Deng S, et al. Ontology-enhanced Prompt-tuning for Few-shot Learning[C]//Proceedings of the ACM Web Conference 2022. 2022: 778-787.