
ChatKBQA: A Generate-then-Retrieve Framework for Knowledge Base Question Answering with Fine-tuned Large Language Models
第一作者:Haoran Luo, Haihong E
作者单位:北京邮电大学
发表时间:2024/5
发表期刊:ACL 2024
关键内容:将知识图谱与大模型结合。亮点:通常是先利用知识图谱进行检索,检索结果作为prompt的一部分输入到模型中。而ChatKBQA是先利用LLM生成逻辑形式,再通过无监督方法对实体和关系进行检索替换,从而提升答案的准确率。
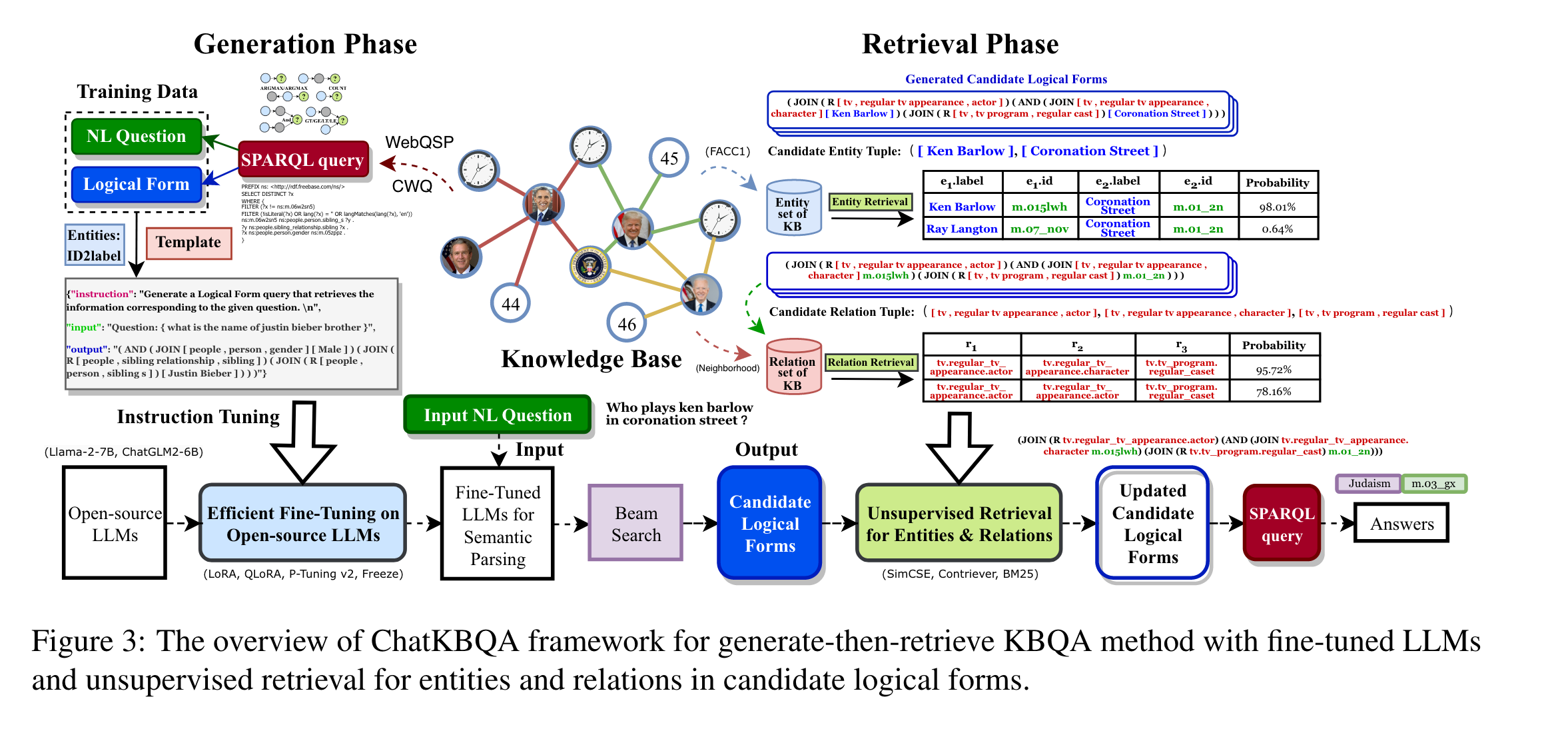
1.引言
KBQA(Knowledge Base Question Answering) 主要有两个核心问题:知识检索、语义解析。
- 知识检索(IR):根据知识库中的问题定位最相关的实体、关系或三元组
- 语义解析(SP):将问题从非结构化自然语言转换为结构化逻辑形式,再将其转换为可执行的图查询,以获得精确的答案和可解释的路径
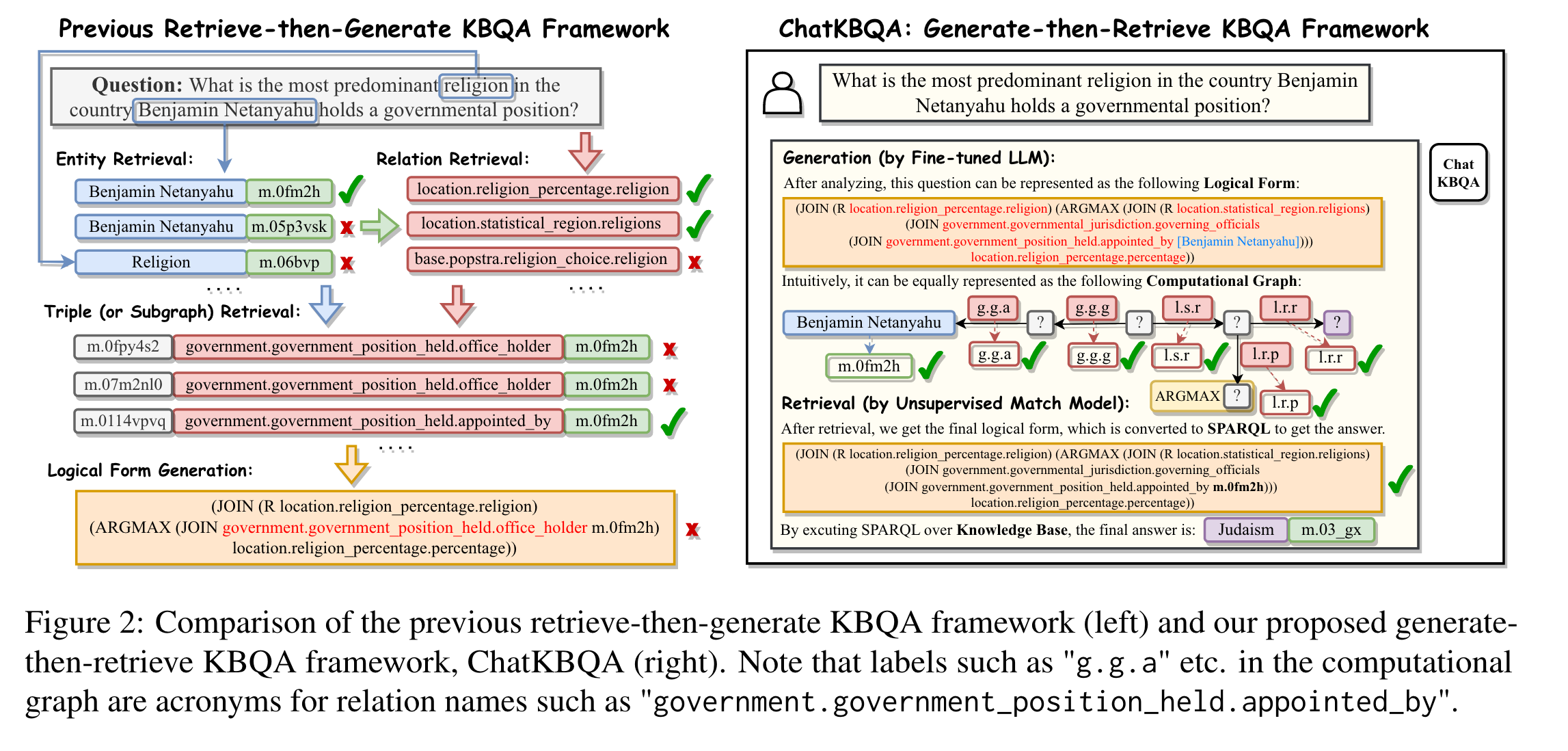
retrieve-then-generate KBQA 框架:先对问题文本进行实体和关系的检索,再进行语义解析。它的不足在于:
-
检索效率低下
Traditional methods first identify the span of candidate entities and then do entity retrieval and relation retrieval. Since the structure of natural language questions differs from KB facts, most approaches require training dedicated models for extraction and linking inefficiently.
-
不正确的检索结果会导致错误的语义解析
Previous methods have utilized retrieved triples also as input of reference to the seq2seq model along with the original question. However, since the retrieved triples are not always accurate, they adversely impact semantic parsing outcomes. Additionally, if there are numerous retrieved triples, the seq2seq model requires a much longer context length.
-
多处理步骤使KBQA成为一项极其复杂的任务
Previous work decomposed the KBQA task into multiple sub-tasks, forming a complex pipeline, which made reproduction and migration challenging.
2. 方法
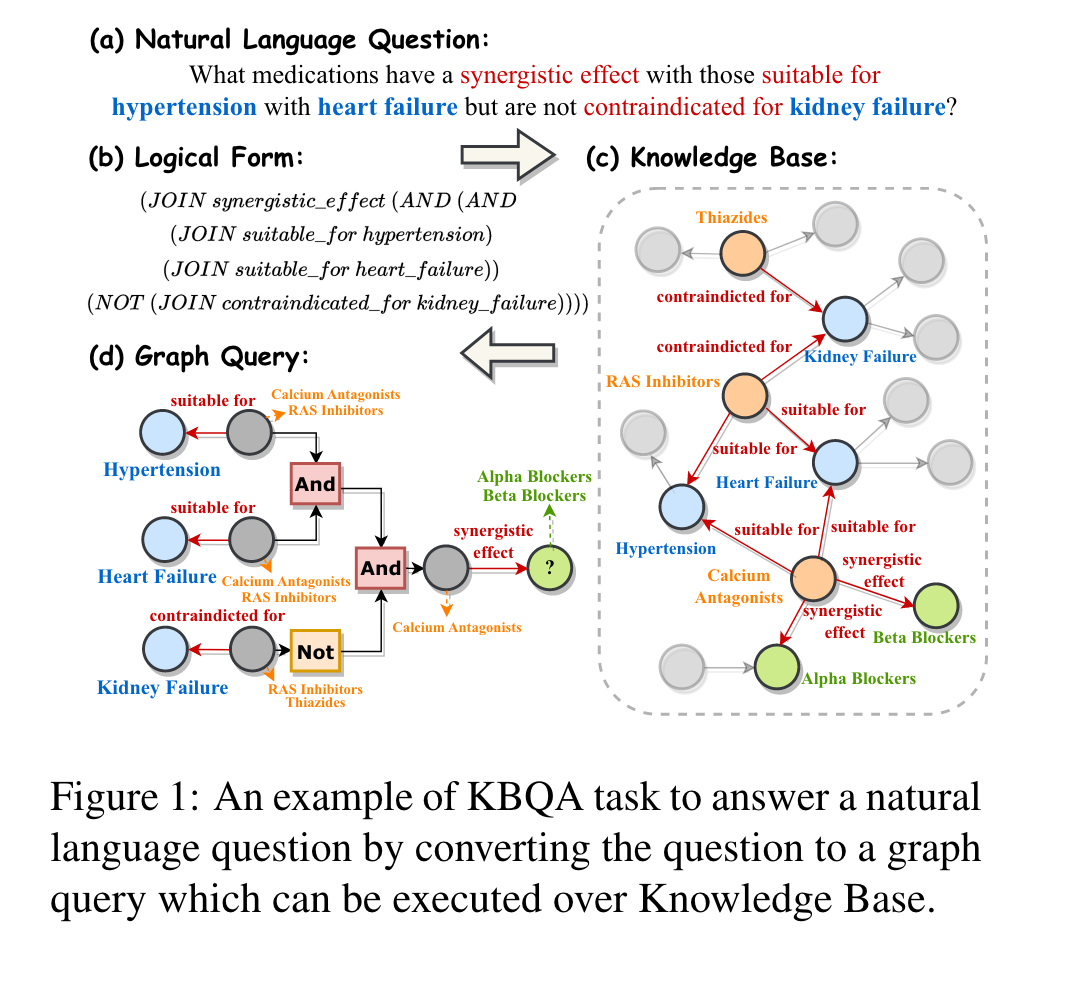
无监督检索,它的原理是:首先计算实体与其它实体的相似度,保留前 k 个及概率大于阈值 t 的相似实体,对实体进行替换,再保留前 k 个及概率大于阈值 t 的相似实体。对关系的检索替换操作类似。

3.实验
从以下几个角度开展实验:
-
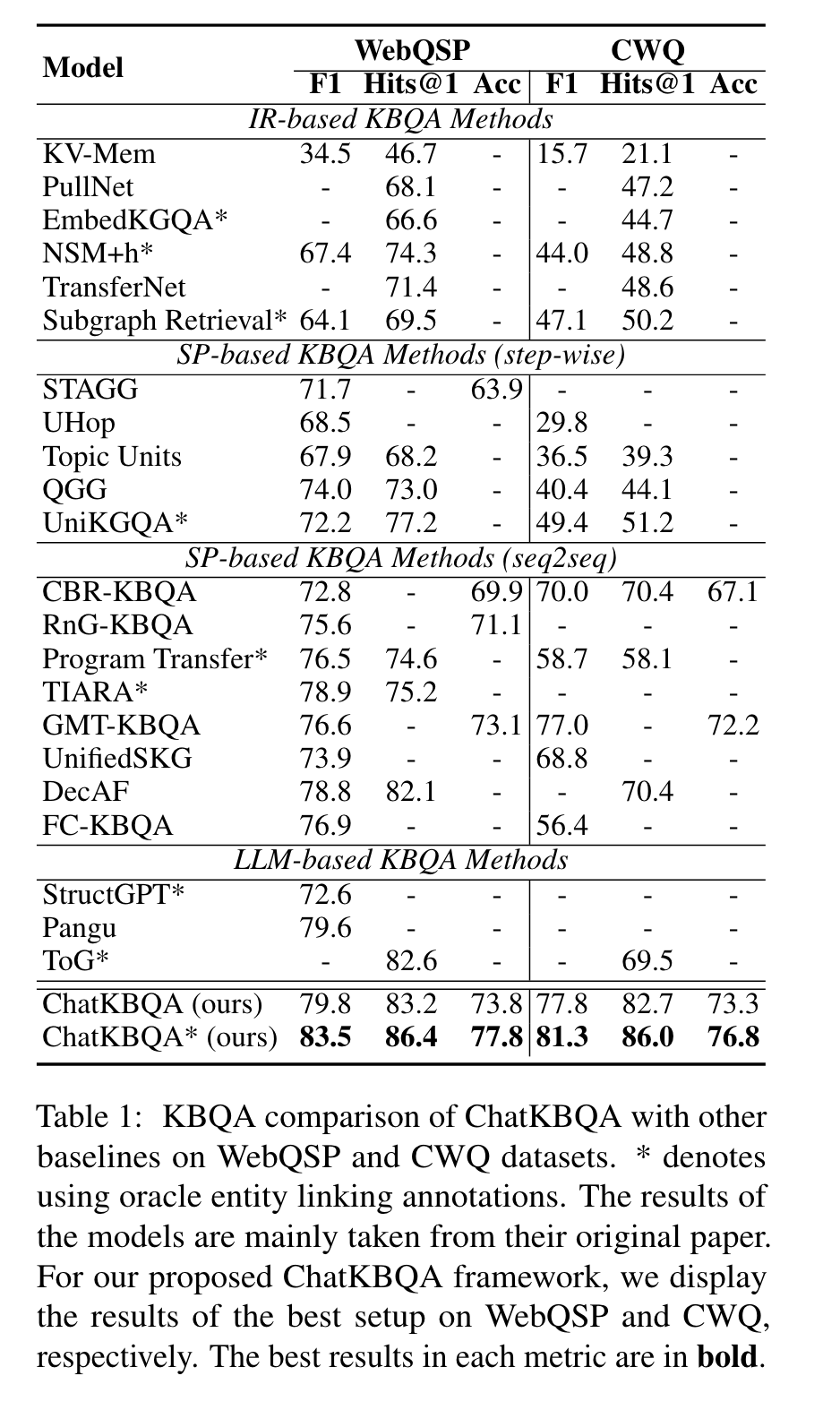
Does ChatKBQA outperform other KBQA methods?
在WebQSP与CWQ两个数据集上进行测试,将ChatKBQA模型与其它模型的效果进行对比。
-
Does the main components of ChatKBQA work?
消融实验,如下图(a)(b)所示

-
Why use Generate-then-Retrieve method instead of Retrieve-then-Generate method?
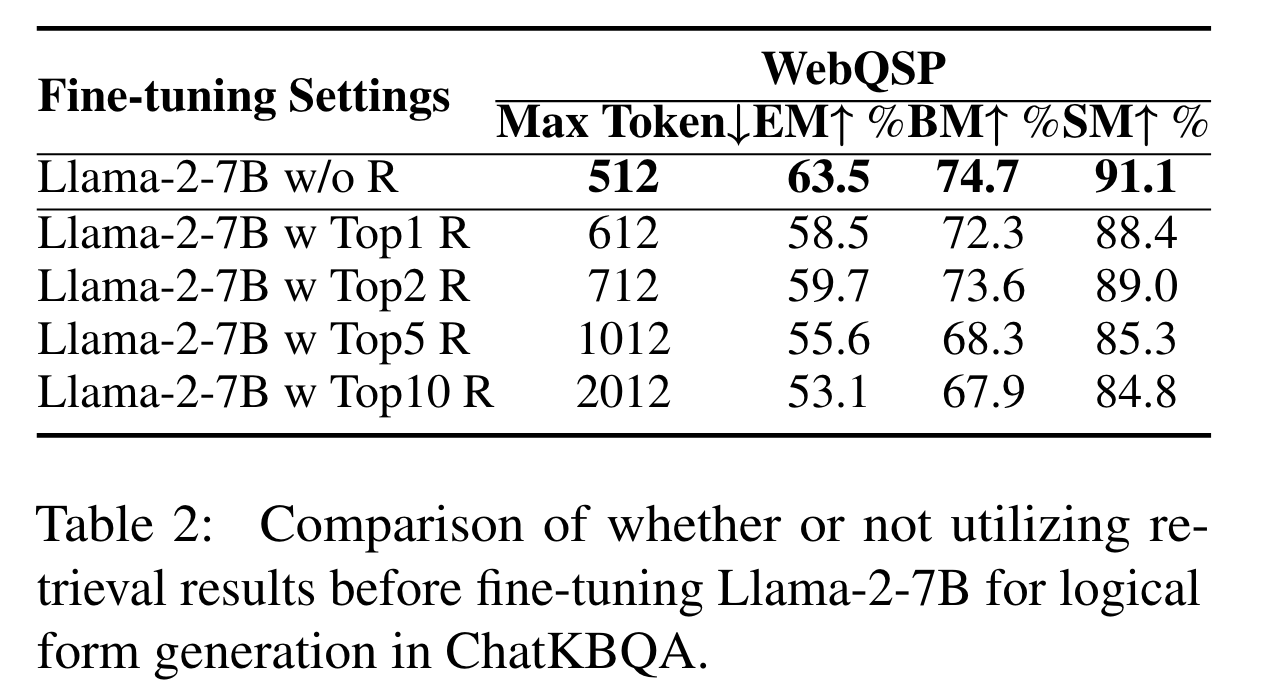
Topk指标:前k个预测结果中有一个为正确即为正确。结果分析:检索得到的信息会有错误的干扰信息和增加指令的Max Token,这导致LLMs对原始问题的灾难性遗忘,增加了训练的难度。 -
Why use fine-tuned open-source LLMs instead of calling ChatGPT or training traditional T5 models?
结果如上图©所示。
-
Does Generate-then-Retrieve method improve retrieval efficiency?
为了体现"Generate-then-Retrieve"方法对检索效率的提升,将逻辑形式生成后的实体检索( ER )和关系检索( RR )与传统的自然语言问句检索( NL-R )进行比较。我们将检索的效率定义为待检索文本与检索答案集合之间的平均相似度范围[0,1],通过不同的检索模型对其进行评分。结果如上图(d)所示。
-
Does ChatKBQA has plug-and-play characteristics?
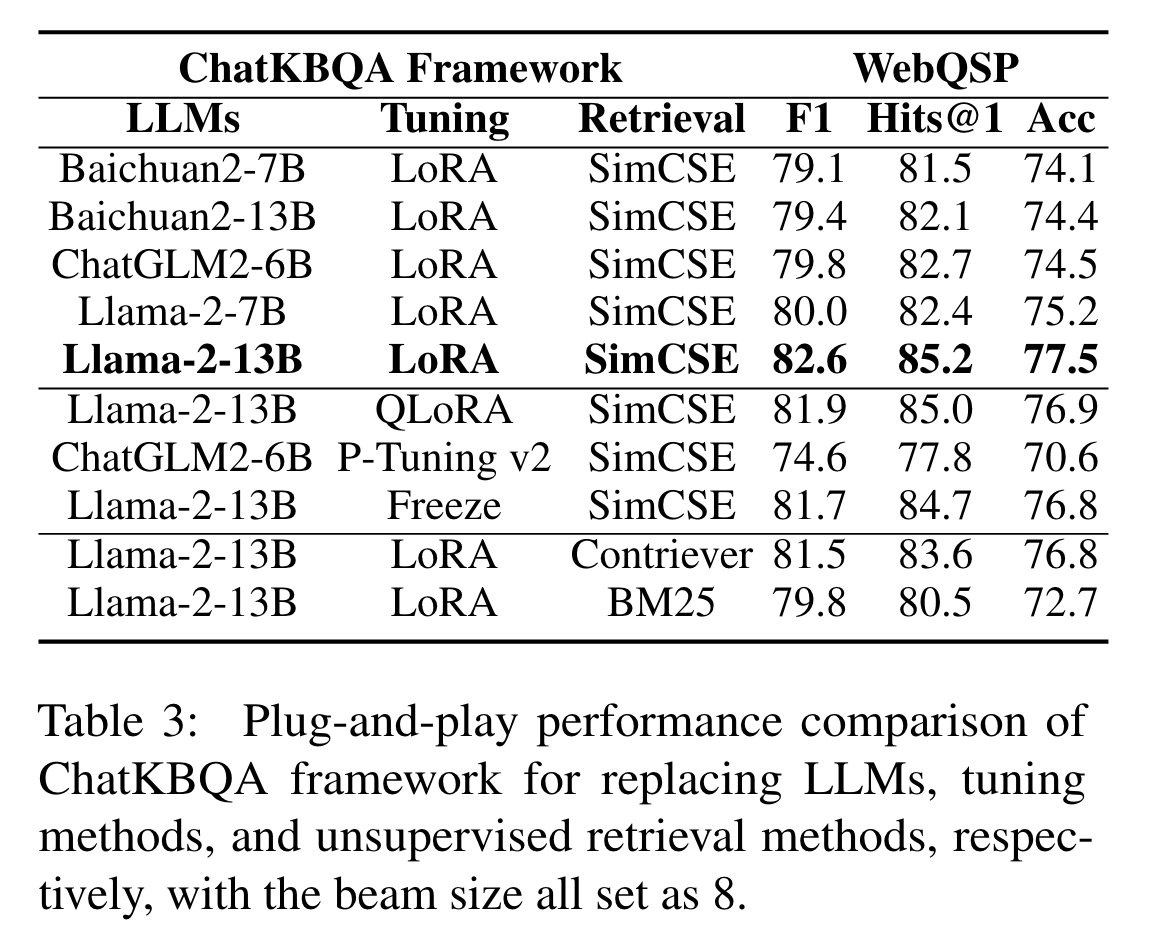
说明ChatKBQA框架可以适用于多种 基座模型+微调方法+检索方法 的组合搭配。
4. 参考文献
Luo H, Tang Z, Peng S, et al. Chatkbqa: A generate-then-retrieve framework for knowledge base question answering with fine-tuned large language models[J]. arXiv preprint arXiv:2310.08975, 2023.