
Agent-Pro: Learning to Evolve via Policy-Level Reflection and Optimization
第一作者:Wenqi Zhang
作者单位:浙江大学
发表时间:2024/6
发表期刊:ACL 2024
关键内容:在拥有不完整的环境信息、多智能体共存的环境下,实现Agent与环境的动态交互学习。它将策略学习转化为prompt 优化过程。环境返回为世界模型和行为策略(将二者放在prompt中生成自我信念和世界信念),在训练中不断优化世界模型和行为策略、自我信念和世界信念(放在prompt中生成行动)。在二十一点、德州扑克两个游戏中进行测试。

1.引言
LLM-based agent 存在的两个常见问题:
- 假设agent能拥有环境的所有信息,但多数情况下不能满足这个条件。此外更多的依赖与提示工程。
- agent 无法从与环境的交互中获得进步
Agent-pro:在拥有不完整的环境信息、多智能体共存的环境下,实现与环境的动态交互学习。它将策略学习转化为prompt 优化过程,在21点、德州扑克两个游戏中进行测试。
2.方法
self-belief:agent 的自我认知。对于德州扑克来说,Agent-Pro对自己的手牌、计划和潜在风险的理解构成了它的自我信念。
social-belief:agent 对环境的认知。对于德州扑克来说,Agent-Pro对对手的猜想构成了它的世界信念。

2.1 Belief-aware Decision-Making Process
K个玩家:$op_1,op_2,\dots,our,\dots,op_K$。第$t$轮时,当前agent拥有的私人信息 $s_t$,公共信息 $o_t$,行动 $a_t$,玩家的自我信念与世界信念 $\xi$。所有玩家的行动$a^{op_1}_t,a^{op_2}_t,…,a^{op_K}_t$,前t轮的轨迹:
$$\begin{array}{r}\mathcal{H}{0: t}=\left{\left(s{0}, o_{0}, a_{0}^{o p_{1}}, a_{0}, a_{0}^{o p_{2}}, \ldots, a_{0}^{o p_{K}}\right),\right. \\vdots \\left.\left(s_{t}, a_{t}, a_{t}^{o p_{1}}, a_{t}, a_{t}^{o p_{2}}, \ldots, a_{t}^{o p_{K}}\right)\right}\end{array}$$
在当前行为策略的指导下,Agent-Pro根据自我信念和世界信念生成行动。
2.2 Policy-Level Reflection
对于失败的局面,检查自我信念和世界信念的合理性,并反思失败的原因。有以下四个指标:
Correctness: Whether its beliefs about itself , the game , and its opponents align with the final results.
Consistency: Whether each belief and action is self -contradictory.
Rationality: Whether the beliefs accurately reflect the underlying intentions behind the opponents.
Reasons: Reflect on why it lost to its opponents , which beliefs are problematic , and what the underlying reasons are.
为了校准不正确的信念,AgentPro将这些对自身和外部世界的反思和分析总结为具体的指令:行为策略和世界建模,其中前者代表了该任务的广义行为策略,后者代表了它对自身和外部世界的理解和猜想。以德州扑克为例,Agent-Pro总结了以下内容:

2.3 DFS-based Policy Evolution
基于DFS的策略迭代:先进行策略评估,再进行策略搜索。
3.实验
3.1 二十一点
- 不同模型不同策略对比。Compared to ReAct and Reflexion, Agent-Pro is more robust. We find that this is due to the effective behavioral guidelines summarized by policy-level reflection. For instance, Agent-Pro summarizes two instructions as follows: 1-When you have achieved a relatively stable total hand value, choosing not to take risks is a good decision. 2-Analyze the dealer cards in World-belief,…, excessive risk-taking can lead to unfavorable outcomes… These self-summarized instructions can alert Agent-Pro to the risks associated with action Hit, thus making more rational decisions.
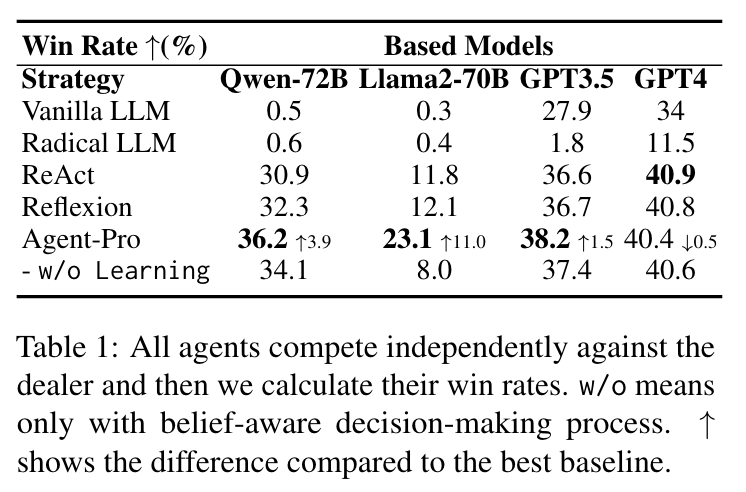
- Agent-Pro is More Rational than Baselines. 其中,Hit为拿牌的意思,代表Agent是否愿意冒险。
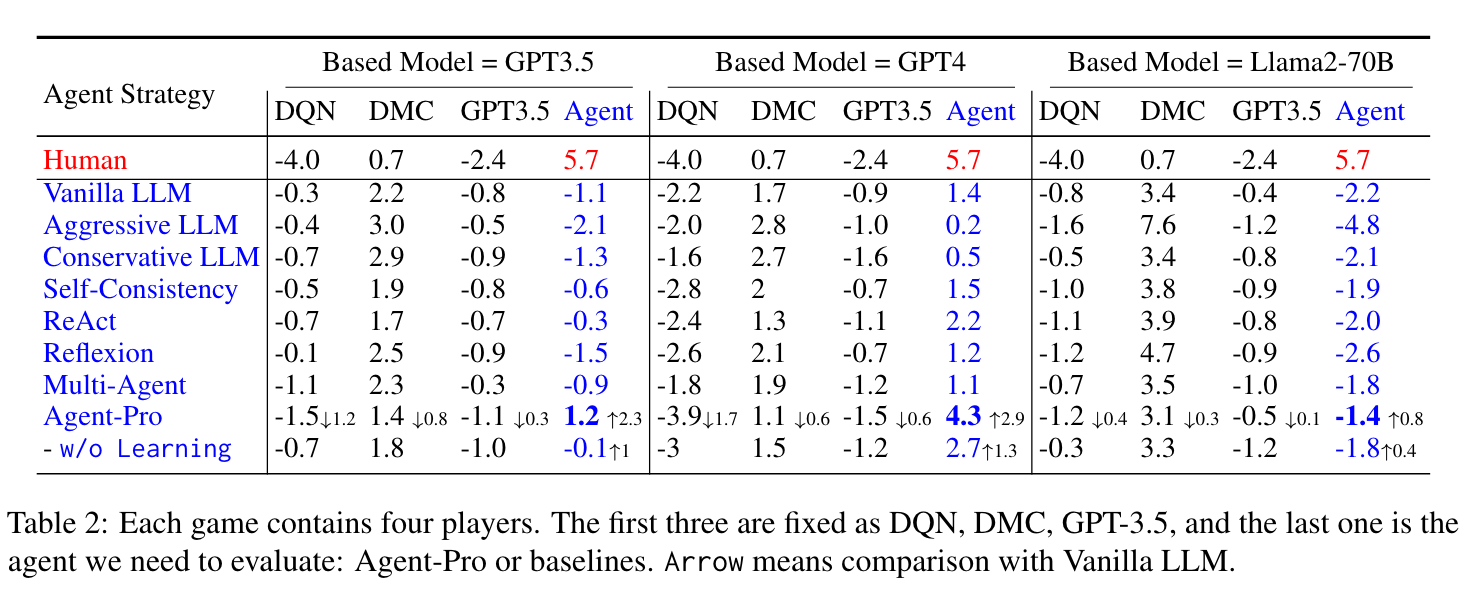
3.2 德州扑克
- 各种基于 LLM 的Agent与其他三个玩家(DQN、DMC、GPT-3.5)的最终筹码数。
- 基于 不同LLM 的Agent 的风格分析
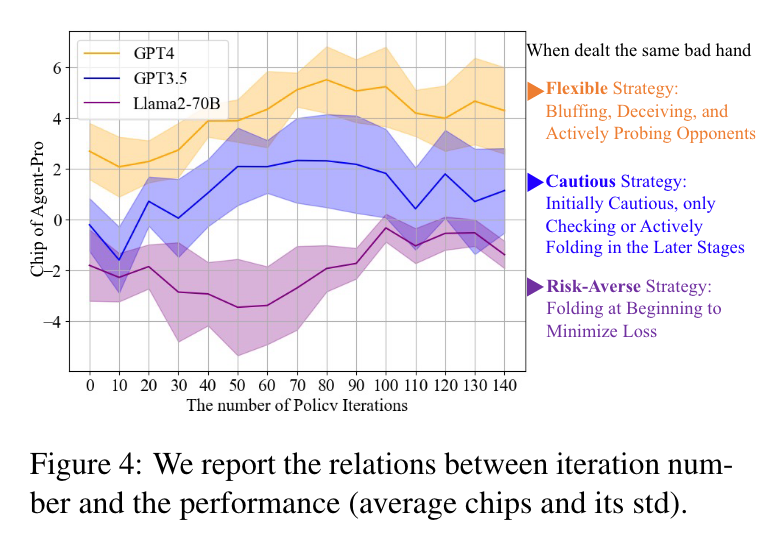
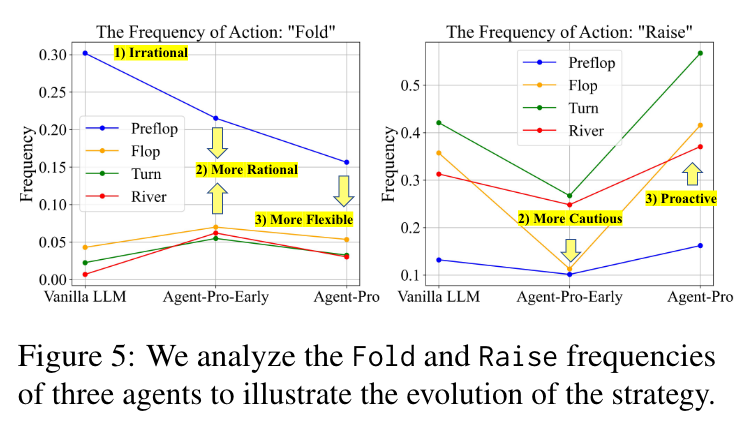
- Agent-Pro策略的演变。
- Fold,弃牌
- Raise,加注
- PreFlop(翻牌前):每局游戏的第一个阶段。在这个阶段,每位玩家会先拿到两张底牌(也叫暗牌),然后进行第一轮下
- Flop(翻牌):游戏的第二个阶段。在这个阶段,桌面上会发出三张公共牌(即大家都可以看到并使用的牌),然后进行第二轮下注。
- Turn(转牌):游戏的第三个阶段。在这个阶段,桌面上会再发出一张公共牌,使得公共牌的总数变为四张,然后进行第三轮下注。
- River(河牌):游戏的第四个阶段。在这个阶段,桌面上会发出最后一张公共牌,使得公共牌的总数变为五张,然后进行最后一轮下注。
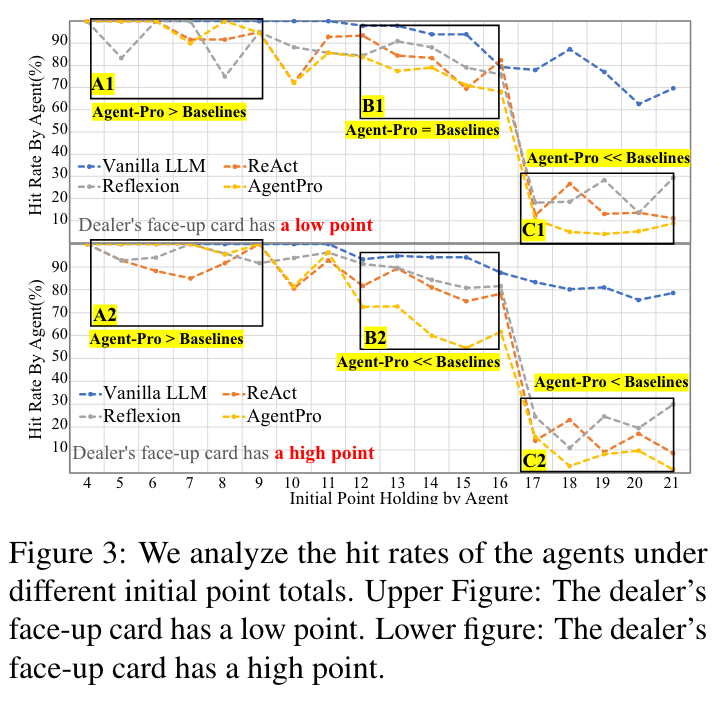
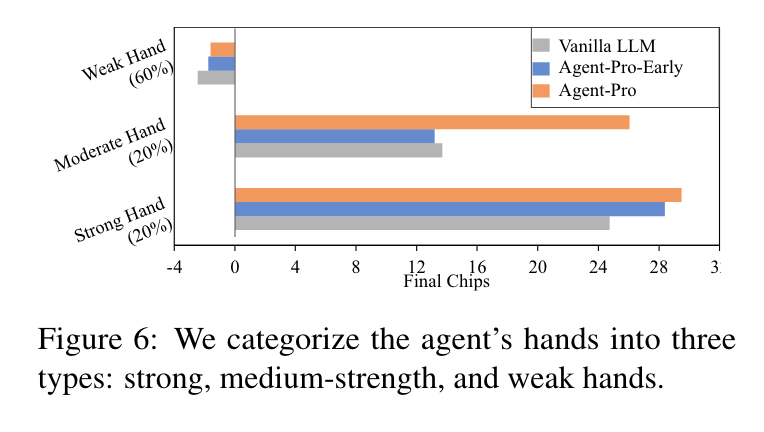
- 不同牌面下Agent-pro的性能分析
4.参考文献
Zhang W, Tang K, Wu H, et al. Agent-pro: Learning to evolve via policy-level reflection and optimization[J]. arXiv preprint arXiv:2402.17574, 2024.