
HeCiX: Integrating Knowledge Graphs and Large Language Models for Biomedical Research
第一作者:Prerana Sanjay Kulkarni
作者单位:PES University
发表时间:2024/7
发表期刊:
关键内容:利用Hetionet 和 ClinicalTrials.gov两个数据库构建了一个生物医药知识图谱,并将KGs与LLMs联合起来。首先利用LLM获取逻辑查询语句,在KGs中进行查询,将查询结果作为上下文输入进行模型推理,并利用LangChain实现流程化。
1.引言
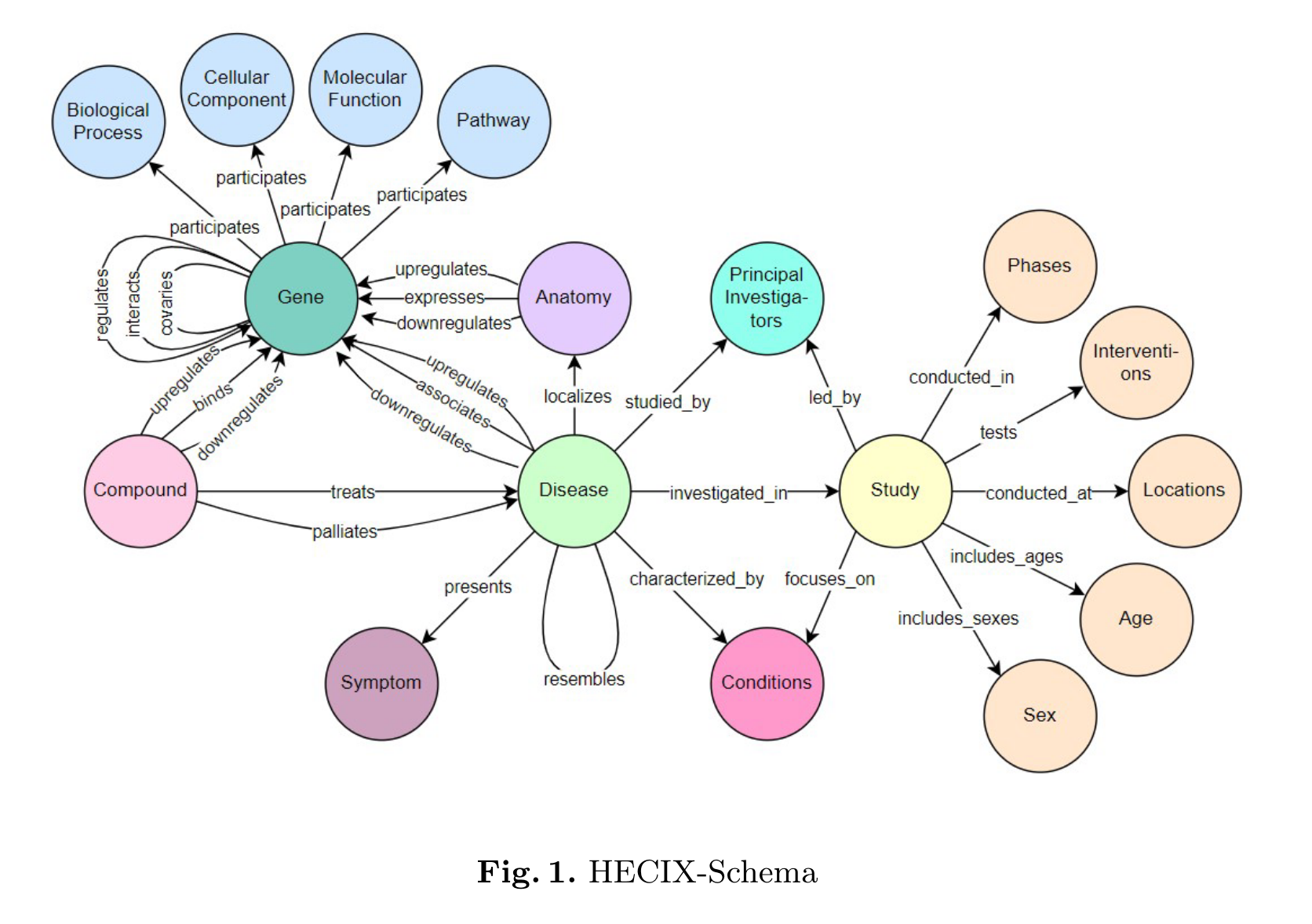
Hetionet 数据库包含了关于疾病、基因和解剖学的大量领域知识,但缺乏关于先前进行的临床试验和实验的充分信息。相反,ClinicalTrials.gov 数据库提供了大量关于临床试验和全球范围内进行的实验的信息,但它对疾病本身提供了有限的见解。对基础生物学和临床试验结果的理解之间的这种差异阻碍了有效的药物开发。因此作者构建了HeCiX KG。
HeCiX-KG 只包含六种疾病,namely Vitiligo, Atopic Dermatitis, Alopecia Areata, melanoma, Epilepsy, and Hypothyroidism. 由6,509个节点和14,377条边组成。
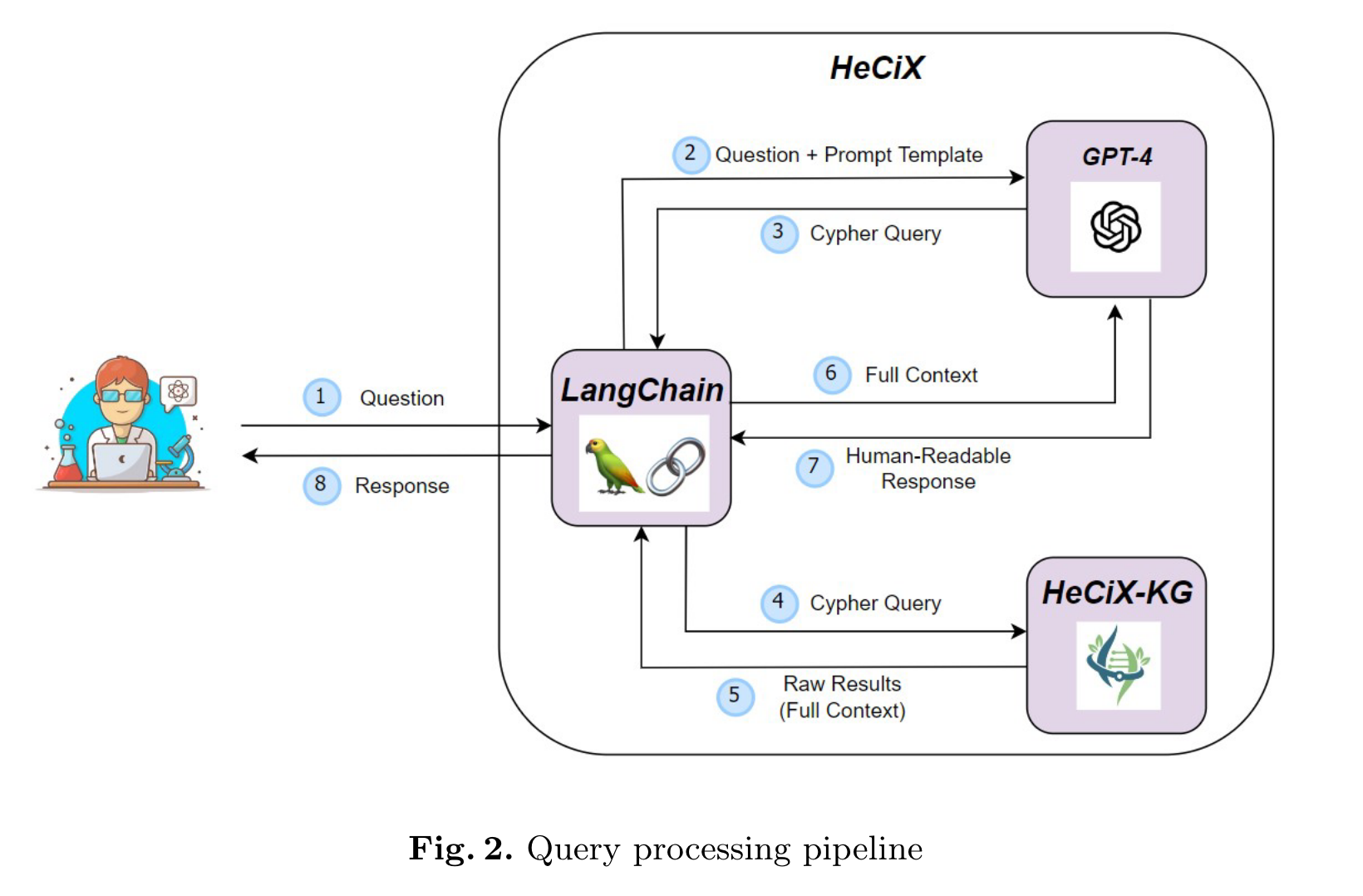
注意这个方法与RoG的区别,RoG中首先要求LLM返回有助于解决问题的关系路径,在KGs上搜索到的检索结果作为模型推理输入,旨在让模型给出正确的回复。在HeCiX的pipeline中,检索结果作为输入,只是要求模型给出对结果的解释。
2.实验
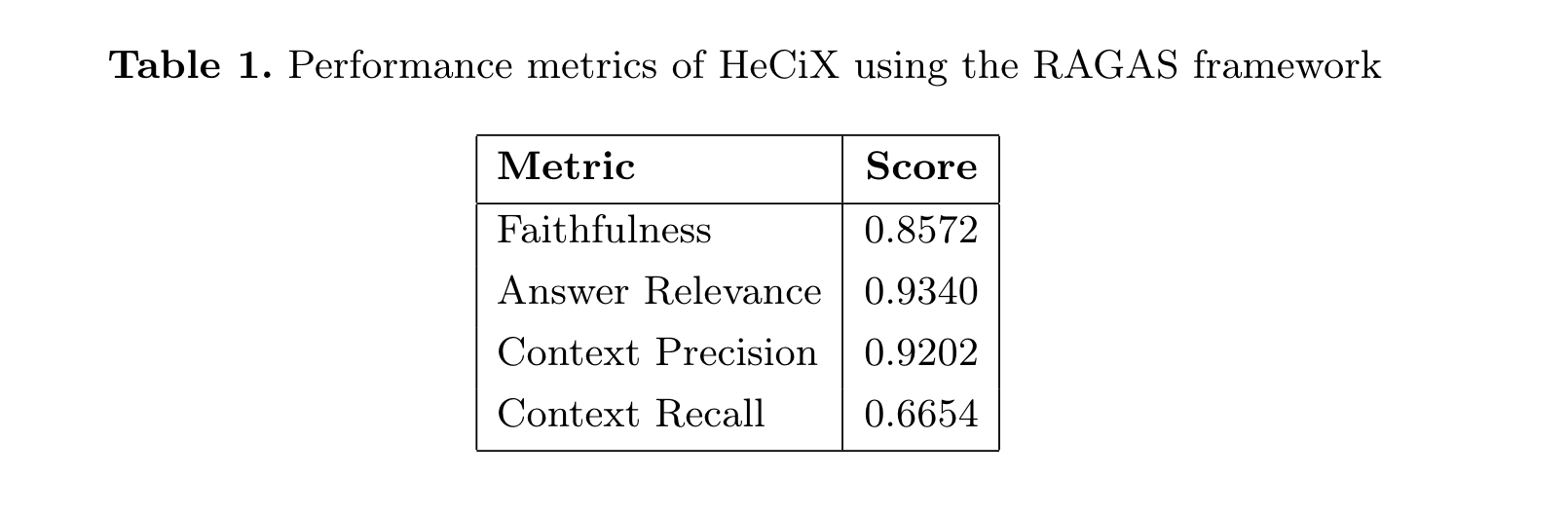
使用RAGAS 框架来评估模型的性能。该框架计算了几个关键指标:
- faithfulness, 生成答案相对于问题和上下文的事实一致性。
- answer relevance, 生成答案与问题的相关程度。
- context precision, 检索到的上下文信息与问题的相关性。
- context recall, 检索器获取回答问题所需的所有相关信息的能力。
3. 参考文献
Kulkarni P S, Jain M, Sheshanarayana D, et al. HeCiX: Integrating Knowledge Graphs and Large Language Models for Biomedical Research[J]. arXiv preprint arXiv:2407.14030, 2024.