
UniMEL: A Unified Framework for Multimodal Entity Linking with Large Language Models
第一作者:Liu Qi, Yongyi He
作者单位:中国科学技术大学
发表时间:2024/7
发表期刊:CIKM 2024
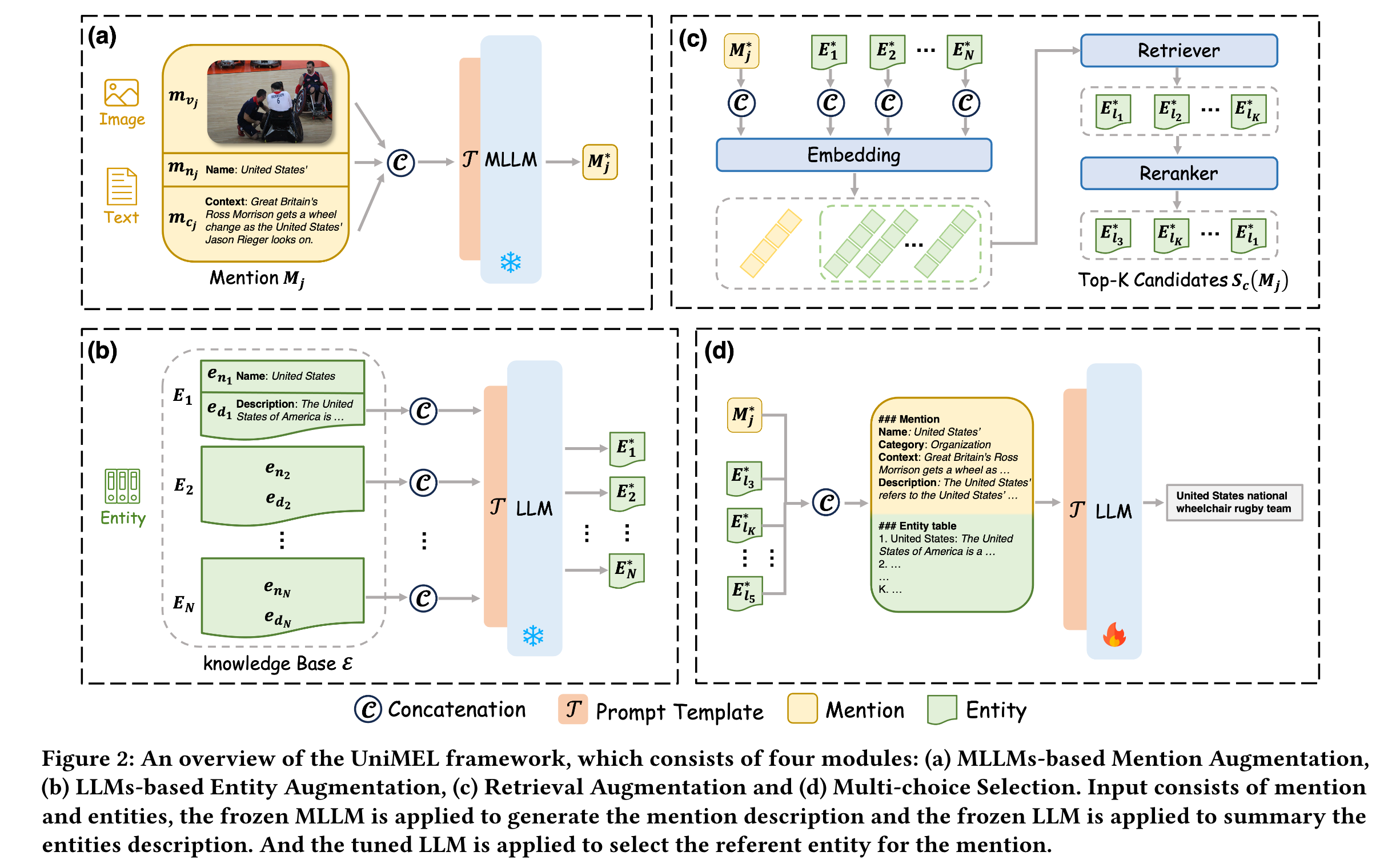
关键内容:提出了实现多模态实体链接的一种框架UniMEL,该框架包含四个部分,LLMs-based Entity Augmentation, MLLMs-based Mention Augmentation, Retrieval Augmentation, Multi-choice Selection。对于entity,认为多模态知识库中的实体描述包含较多不相关的信息,用LLM对实体描述进行精简化。对mention,充分利用图片信息和MLLM的通用能力,将mention作为MLLM的输入,以得到恰当的嵌入表示。再对候选实体集合进行粗粒度筛选,只保留与mention相似度最高的前K个实体集合,再利用LLM进行细粒度的实体单项选择。
1.引言
实体链接:可以分为两步,一是候选生成,二是候选排序。候选排序可以分为两步(粗粒度与细粒度):首先是候选选择,即进行粗粒度过滤(TF-IDF,word2vect等);二是候选实体重排序,通过衡量文本和候选实体的相关性(encoder)来排序。
多模态实体链接(MEL)旨在将多模态上下文中的歧义提及(ambiguous mentions)与多模态知识库中的引用实体(entity)链接起来。

在multimodal knowledge base (MMKB)中,每个实体的静态属性(如职业、姓名)被封装在文本描述中。相反,与文本描述相比,MMKB 中的实体图像往往表现出更广泛的动态属性(如衣服颜色)。如果采用动态属性作为文本实体的描述符,通常会导致在识别实体时误导性地关注这些属性,如下图所示。

MEL 难点:
- Redundant entity descriptions. Generally, the description of the entity is usually too long, leading to a hard focus on valid information in the process of disambiguation. In this case, it is necessary to pay more attention to entities and mentions related parts.
- Lack of important semantic information in mentions. the mention textual context is a truncated piece extracted directly from documents, lacking pivotal semantic information and sufficient evidence for linking the mention to a specific entity effectively. How to utilize images from mentions to supplement their lacking semantic information becomes essential.
- Combining the visual context with the textual context effectively is challenging.
- LLMs lack domain-specific knowledge. Although LLMs demonstrate powerful general capabilities, they do not directly excel in specific domain tasks (e.g., MEL tasks).
UniMEL 提出的解决方案:
- LLMs-based Entity Augmentation。对于实体来说,过于详细和冗余的描述给 MEL 任务带来了极大的挑战。通过利用法学硕士的总结能力,可以获得简短而精确的新描述。
- MLLMs-based Mention Augmentation。对于提及,与提及相关的图像和上下文信息被处理为 MLLM 的输入,以便提取图像与其上下文之间更深层的语义关系。这种方法可以保持原始图像的完整性(即无需裁剪或编码),从而充分利用未更改的原始数据。考虑到用于预训练 MLLM 的广泛语料库,该方法有可能丰富与提及相关的具体信息。
2.方法
- LLMs-based Entity Augmentation

- MLLMs-based Mention Augmentation

- Retrieval Augmentation, 对相似度最高的K个实体进行降序排序(以避免多项选择的顺序对结果的影响),得到候选实体集合
- Multi-choice Selection

UniMEL 采用 LLaMA3-8B 和 LLaVA-1.6 作为默认的 LLM 和 MLLM。
3.实验
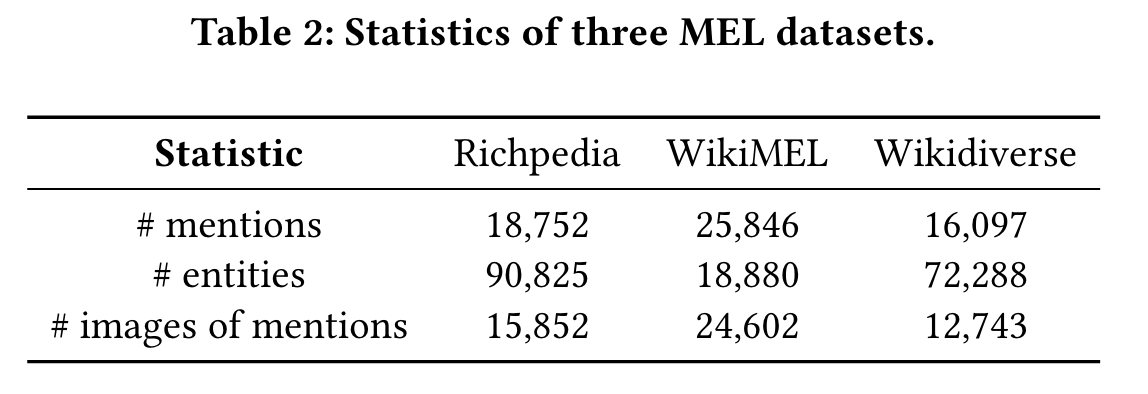
- 实验数据集
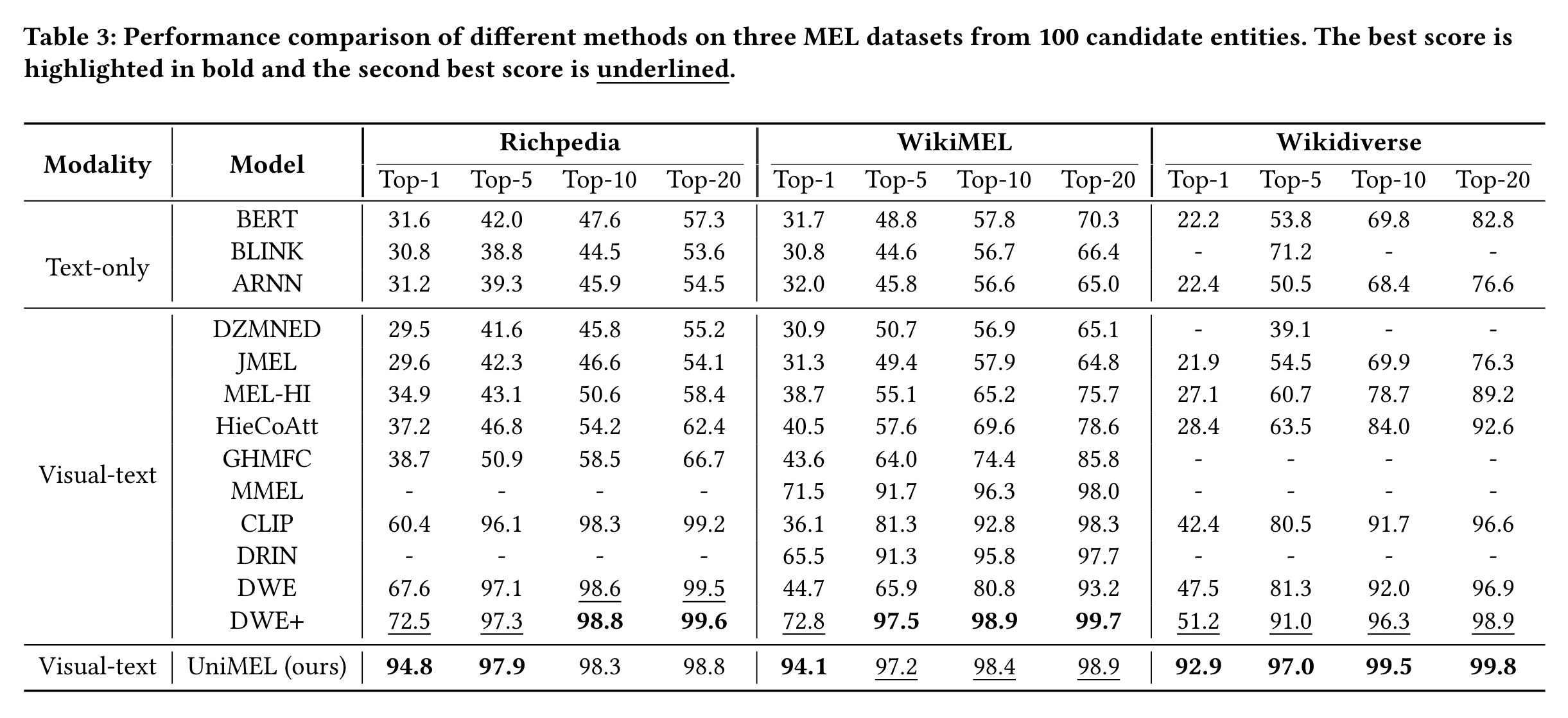
- 在不同模型、不同数据集、不同K值下的测试结果
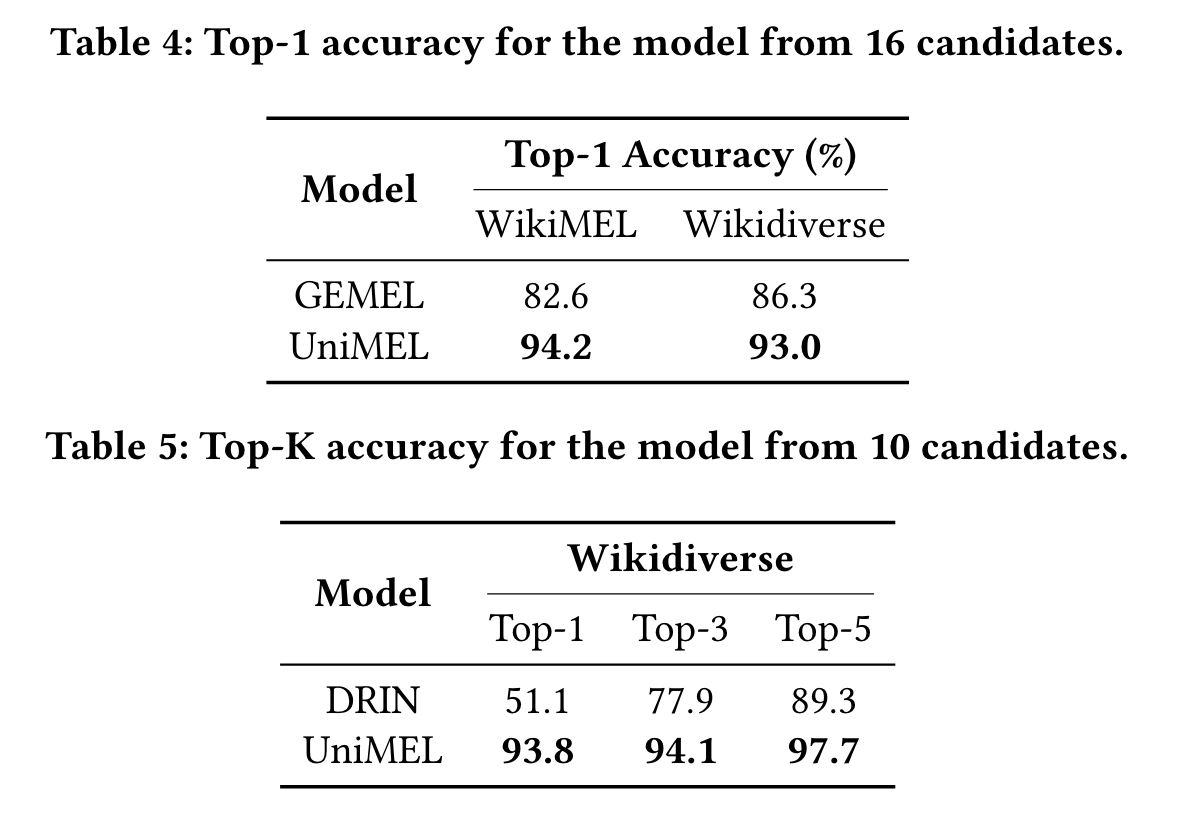
- 与SOTA模型比较,探究K值对结果的影响。Table 4
中候选实体数量为设为16,是为了与SOTA模型GEMEL进行比较。候选实体的数量越少,越容易选择链接实体。
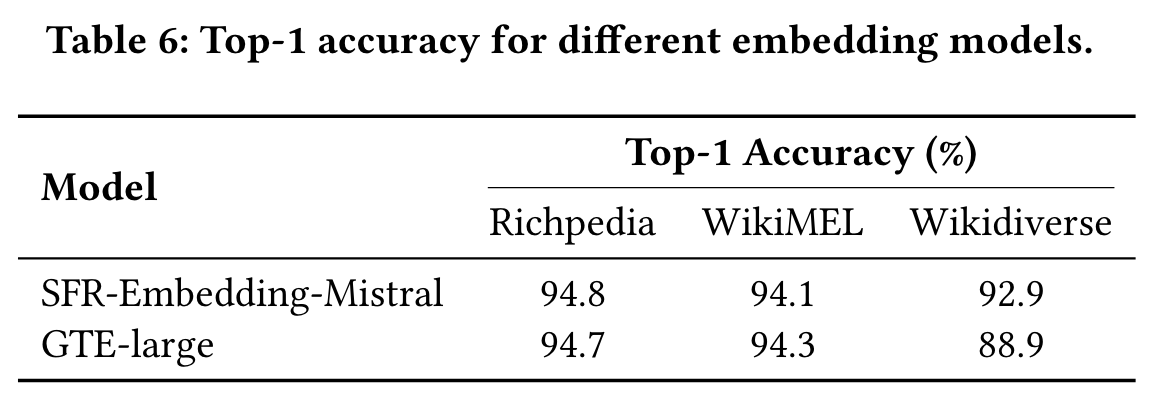
- 不同嵌入模型的比较
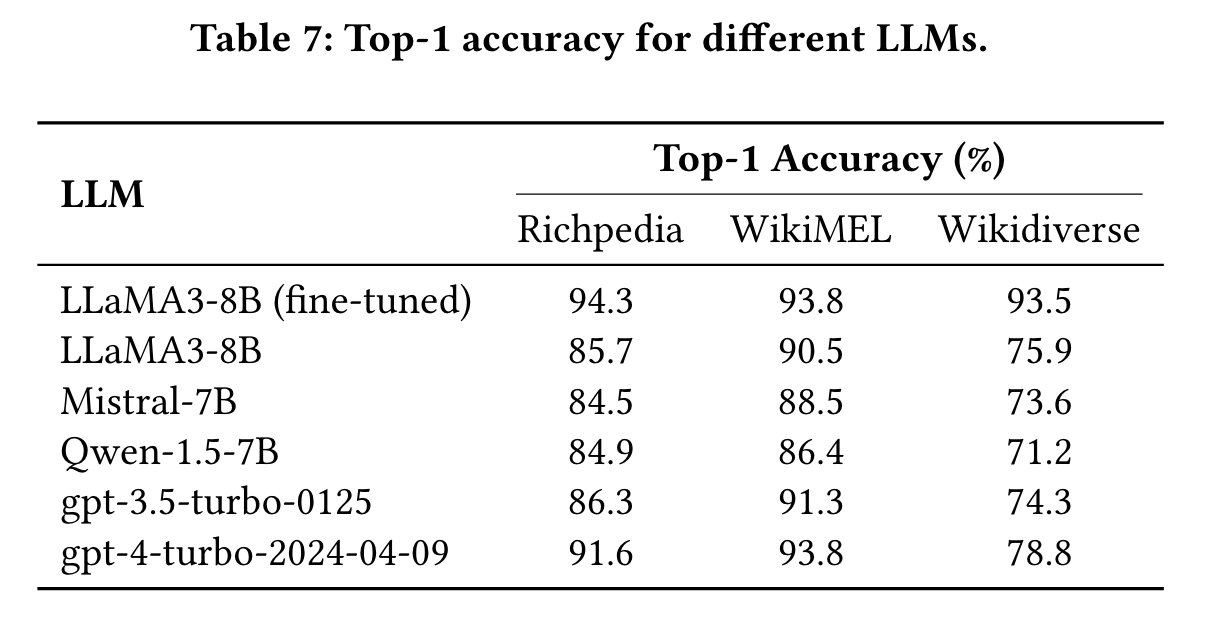
- 不同基座 LLM 的比较
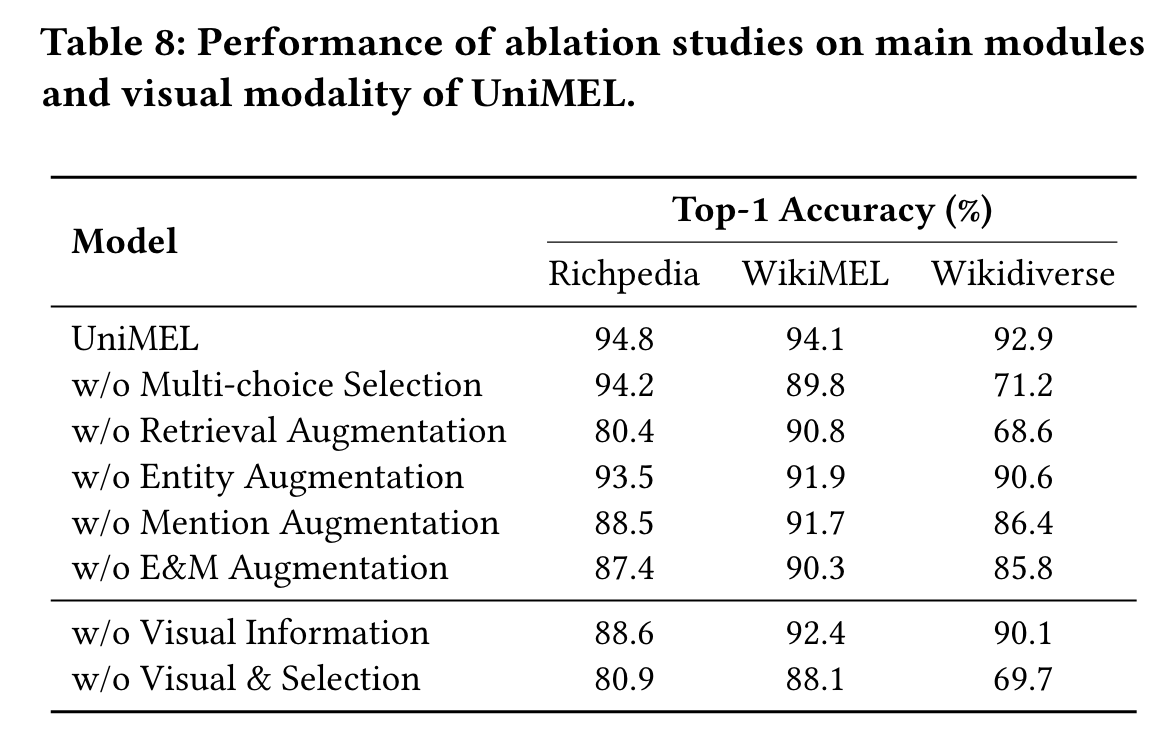
- 消融实验
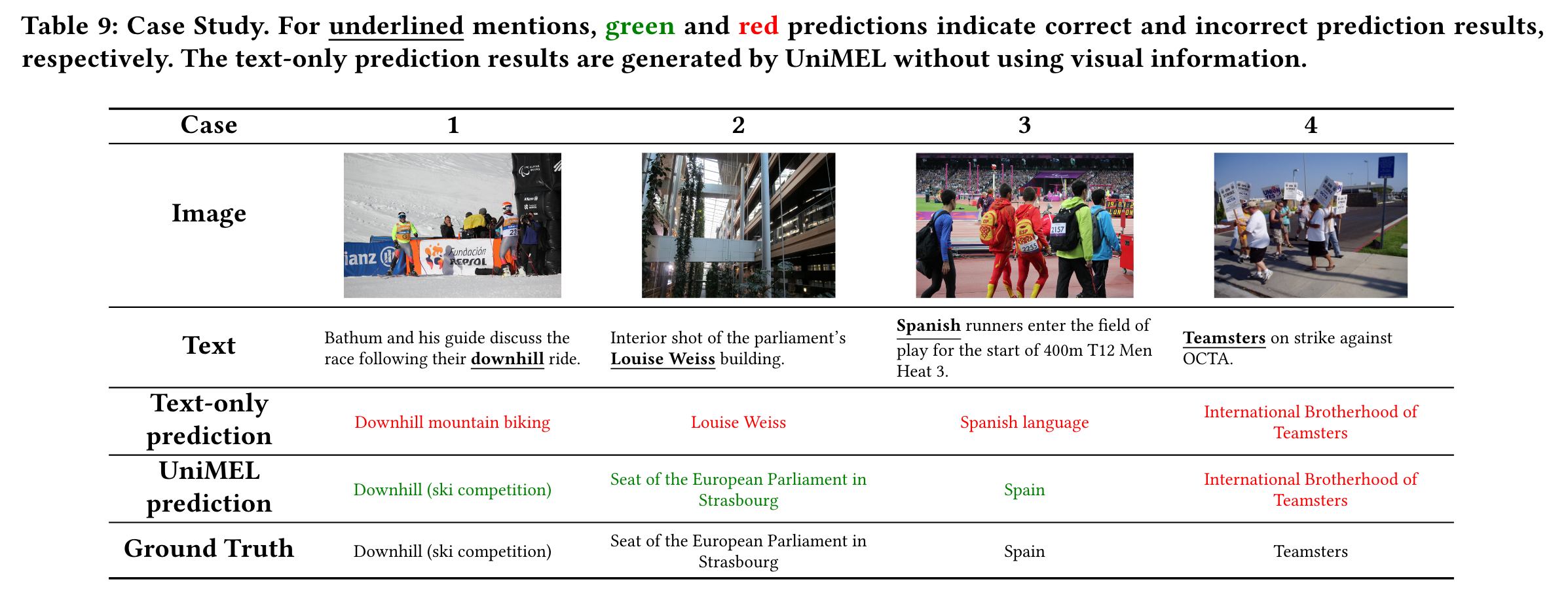
- Case Study
4.参考文献
Qi L, Yongyi H, Defu L, et al. UniMEL: A Unified Framework for Multimodal Entity Linking with Large Language Models[J]. arXiv preprint arXiv:2407.16160, 2024.