
Large Language Models for Generative Information Extraction: A Survey
第一作者:Derong Xu, Wei Chen
作者单位:中国科学技术大学
发表时间:2024/6
发表期刊:
关键内容:介绍三种典型的IE技术:NER,RE,EE的代表性模型,并比较它们的性能;比较用于LLM的不同的IE技术;介绍不同领域的IE工作;提出潜在研究方向;对常用LLM和数据集进行总结。
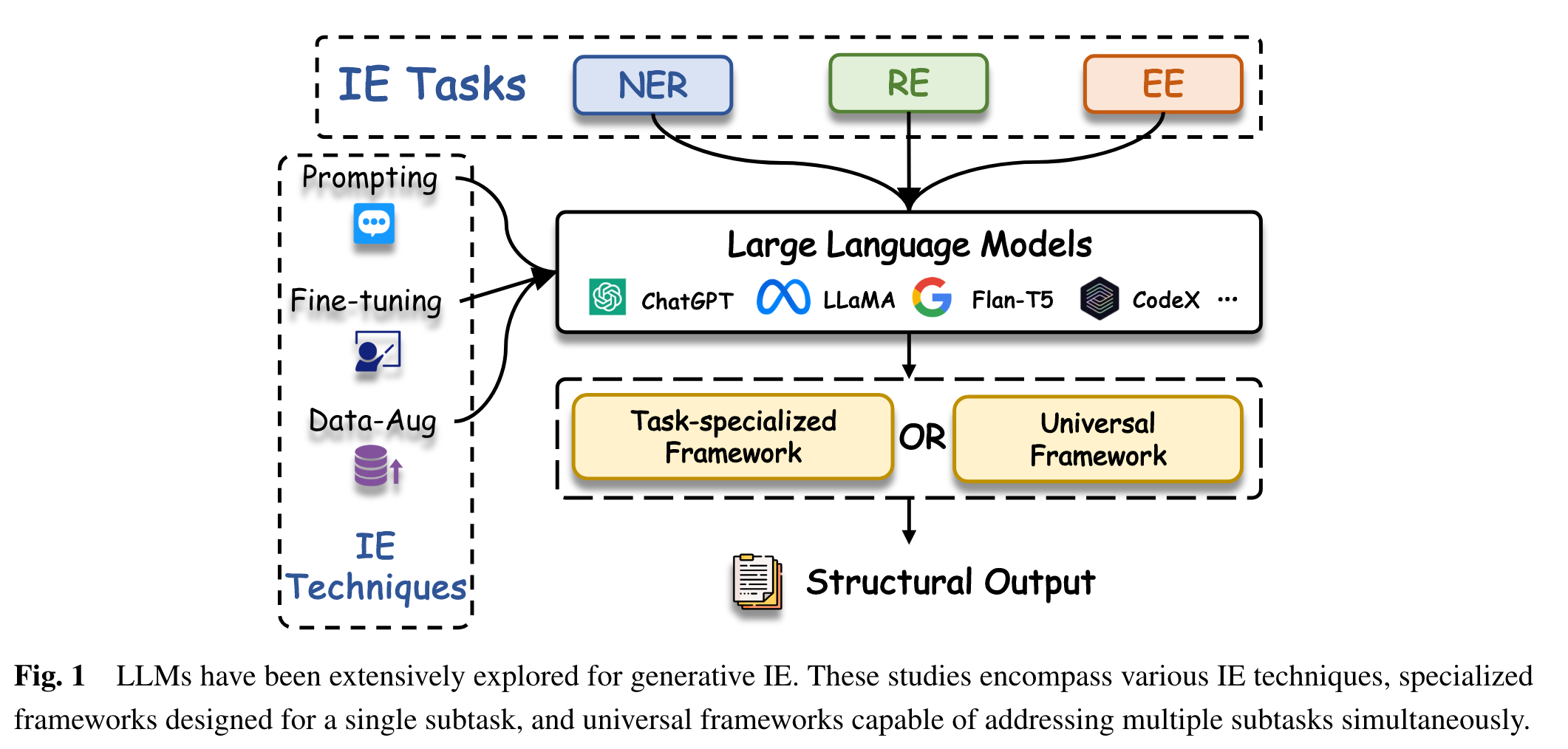
1.LLMs for Different Information Extraction Tasks
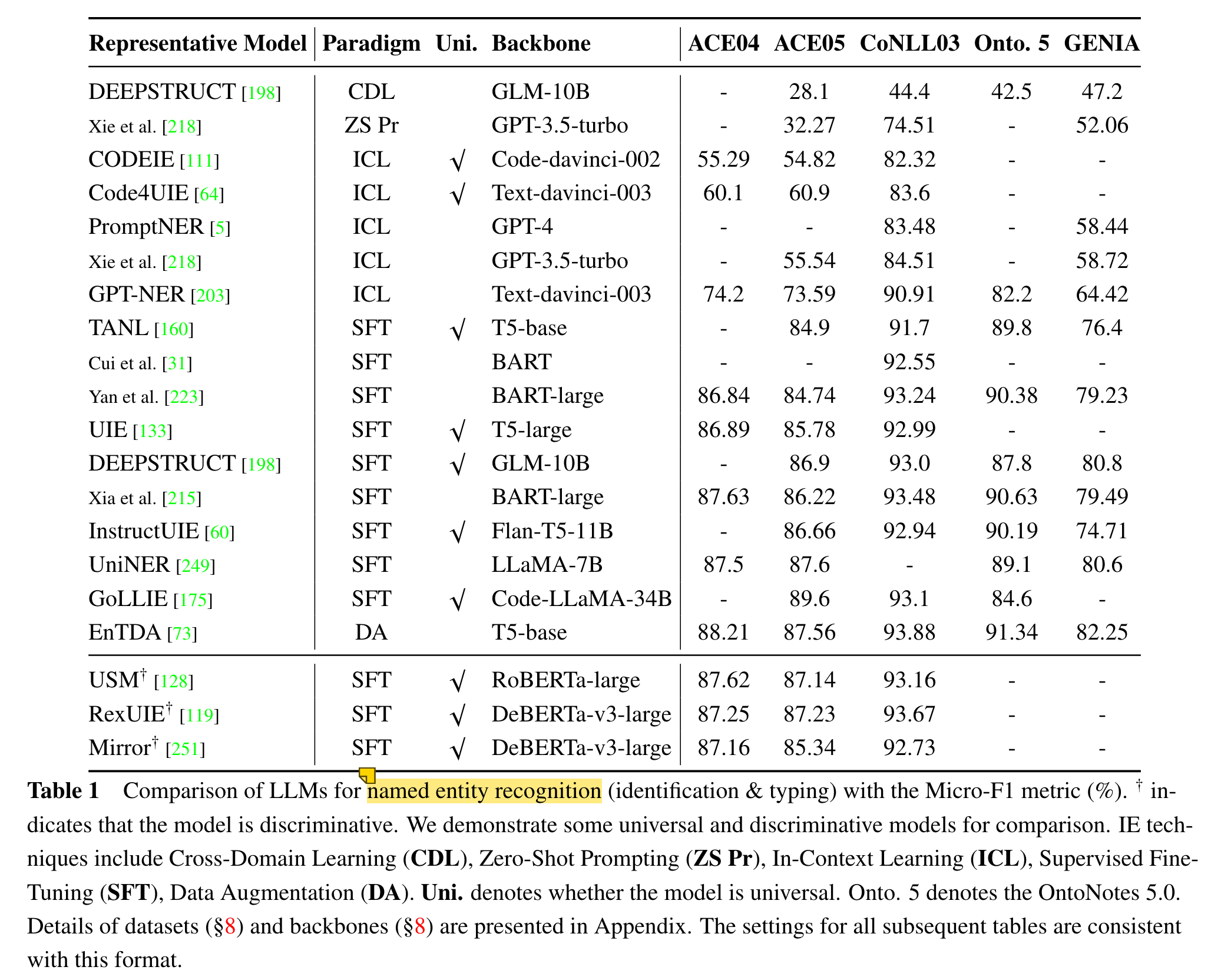
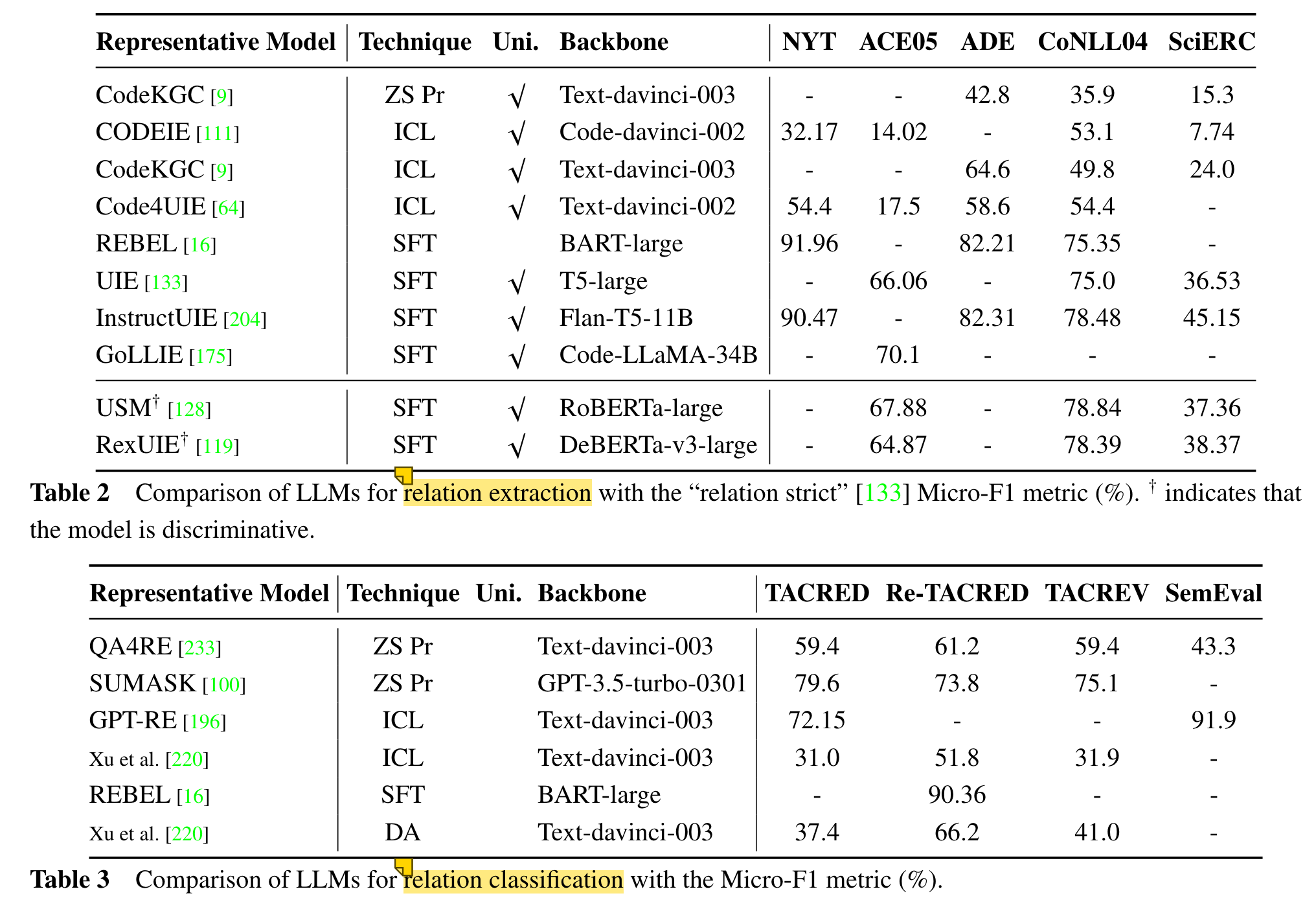
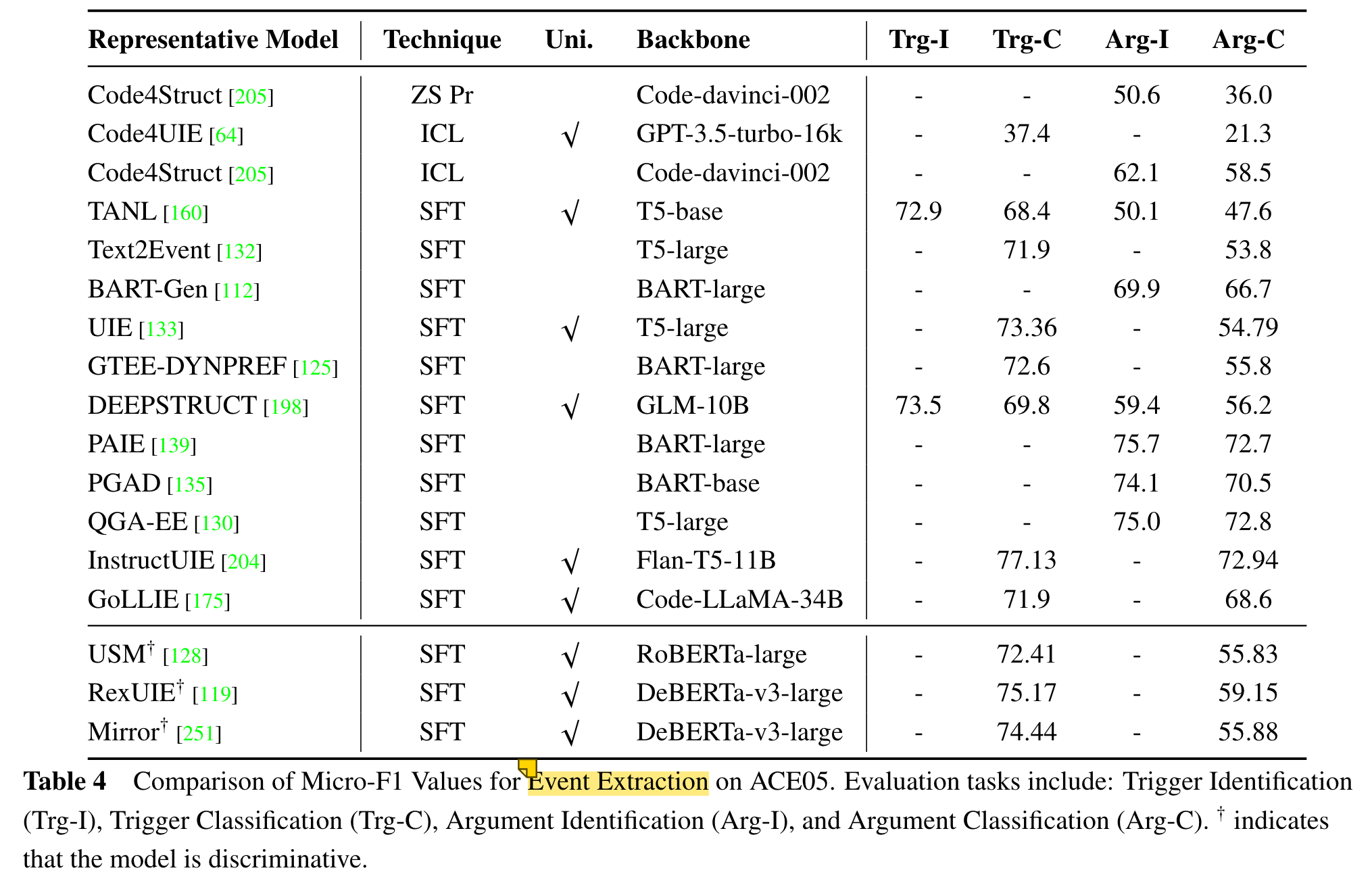
2.Techniques of LLMs for Generative IE

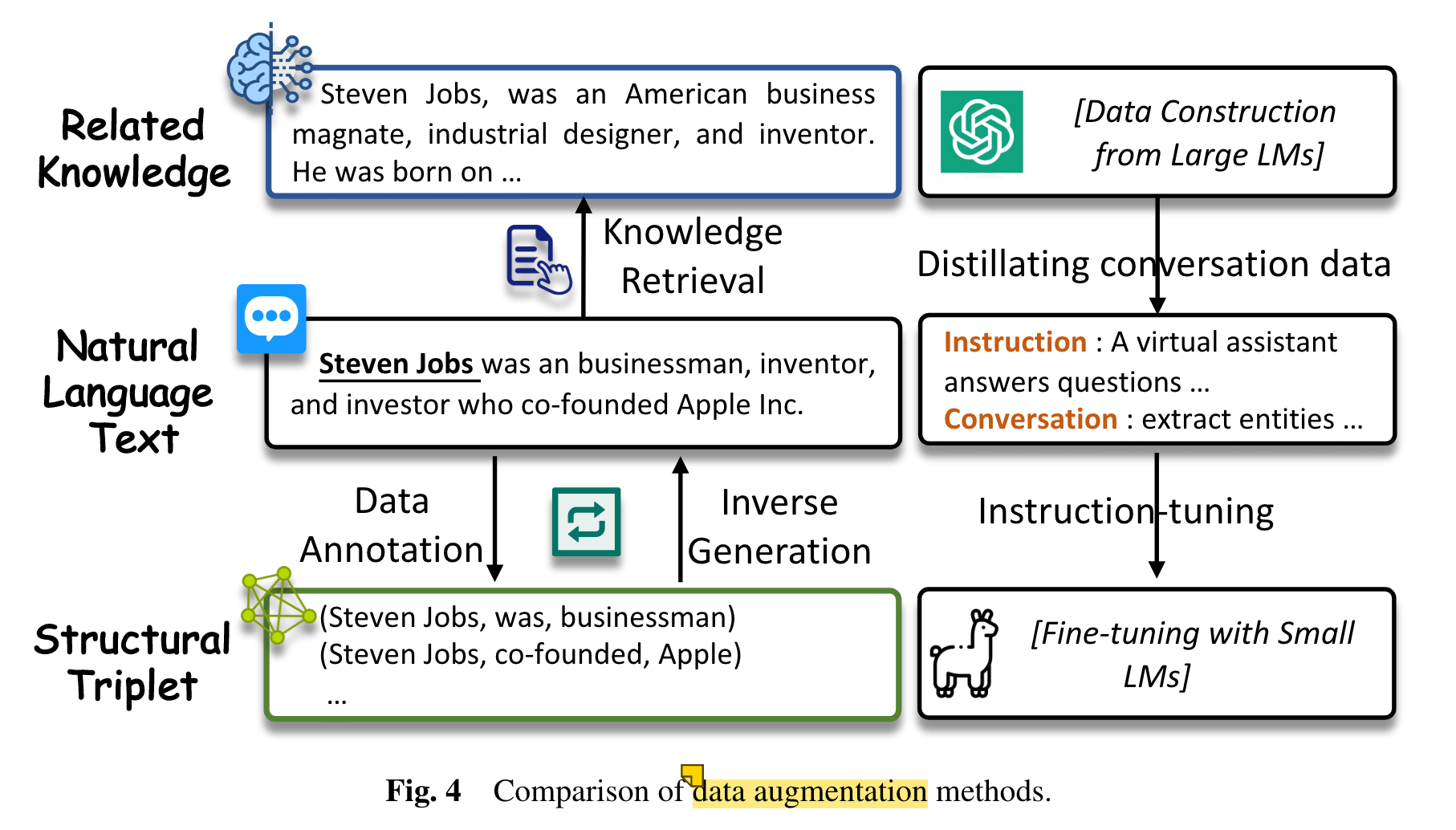
- prompt design:
- Question Answer (QA). 将prompt 修改为QA格式。
- zero-shot
- cross-domain learning. Learn and capture the inter-task dependencies of known tasks and generalizing them to unseen tasks and domains. 对不同领域的泛化。
- cross-type learning,对不同任务类型的泛化,如由某一事件类型泛化到另一事件类型。
- Constrained Decoding Generation。
- 起因:LLMs are primarily designed for generating free-form text and may not perform well on structured prediction tasks where only a limited set of outputs are valid. To address this challenge, researchers have explored the use of Constrained generation for better decoding.
- 含义:Constrained decoding generation in autoregressive LLMs refers to the process of generating text while adhering to specific constraints or rules
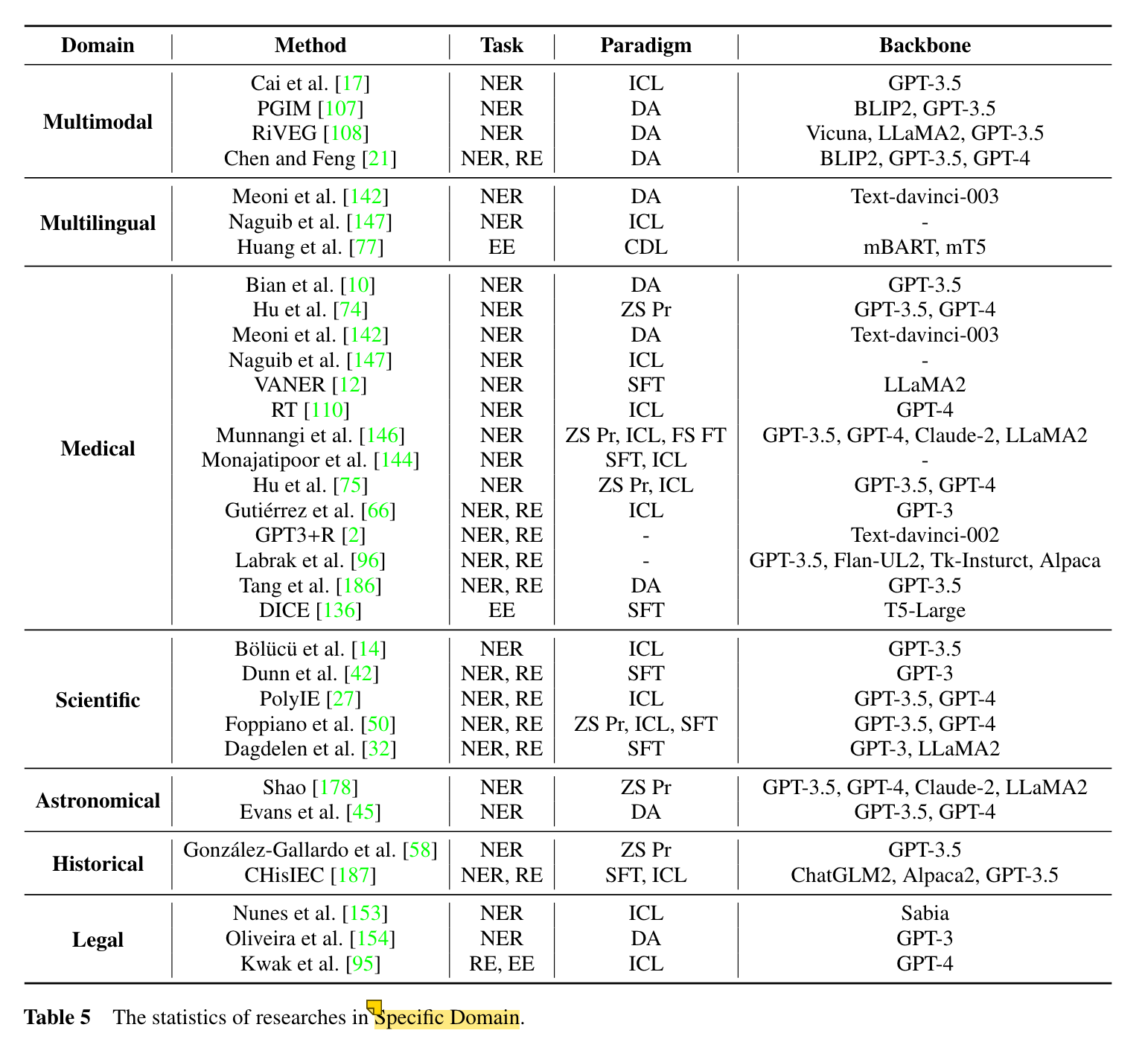
3.Applications on Specific Domains
4.Future Directions
- Universal IE
- Low-Resource IE
- Prompt Design for IE。CoT, interactive prompt design 等技术。
- Open IE, 开放信息抽取。Open IE 中抽取的谓语和实体并不是针对特定的领域,也并没有提前定义好实体类别。更一般的,开放域信息抽取的目的是抽取出所有输入的文本中的形如 <主语,谓语,宾语> 的三元组。开放域信息抽取对于知识的构建至关重要,可以减少人工标注的成本和时间。
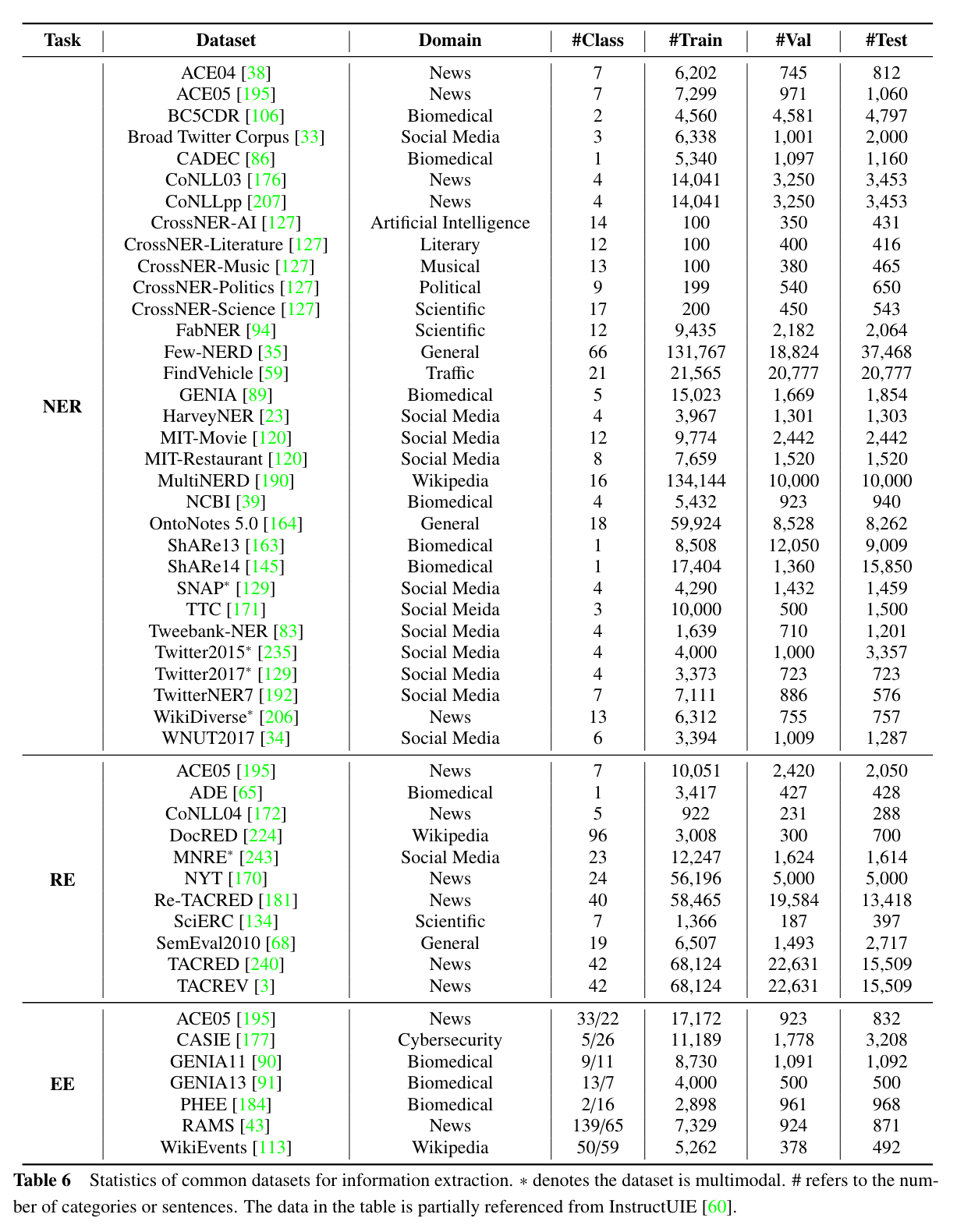
5.Benchmarks & Backbones
6.参考文献
Xu D, Chen W, Peng W, et al. Large language models for generative information extraction: A survey[J]. arXiv preprint arXiv:2312.17617, 2023.
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.