
TnT-LLM: Text Mining at Scale with Large Language Models
第一作者:Mengting Wan, Tara Safavi
作者单位:Microsoft Corporation
发表时间:2024/3
发表期刊:
关键内容:借助LLM实现分类生成、文本分类的自动化。分类生成包括两个阶段:首先对每篇文档进行总结,然后设计三类prompt(类似于SGD,根据总结生成类别、评估并提出修改建议、检查输出类别的格式与质量)。文本分类是指使用LLM对文档进行分类,得到训练数据集。最后,使用该数据集对轻量级分类器进行训练,实现模型蒸馏。
1. 引言
文本挖掘中两个相互关联的核心任务:
- 分类生成:查找和组织一组描述语料库各个方面的结构化规范标签
- 文本分类:对语料库中的文本实例进行标记。
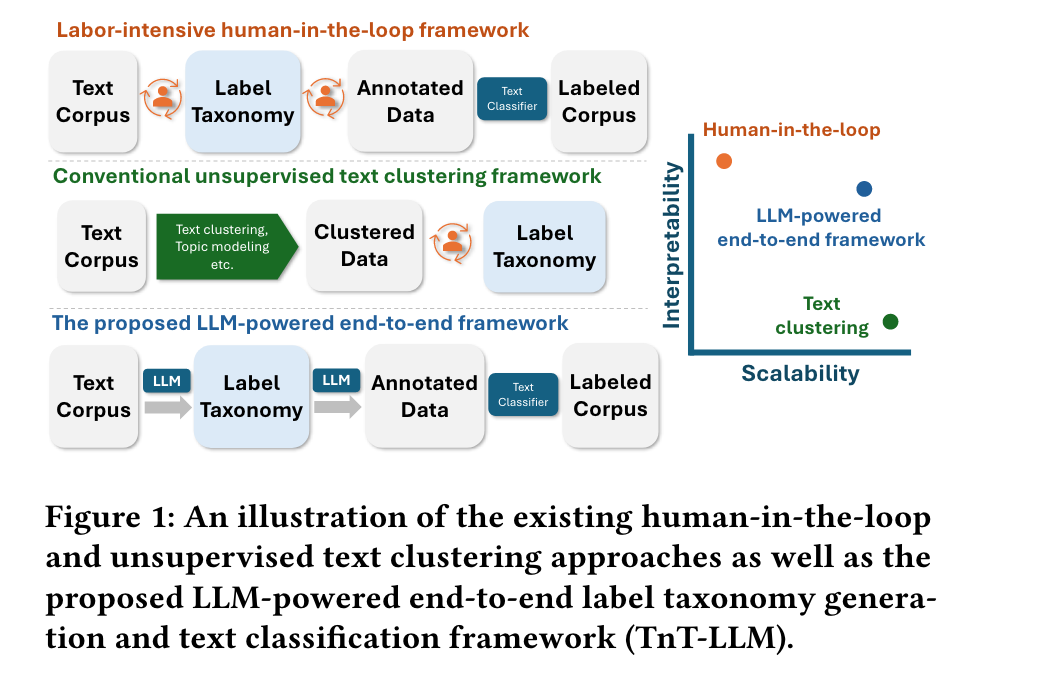
传统的方法有 human-in-the-loop framework 和 无监督机器学习法。
- human-in-the-loop framework:首先人工确定好类别标签,在小部分语料库样本上收集人工注释,训练机器学习文本分类模型。虽然这种人机交互方法提供了较高的可解释性,但它们面临着重大的可扩展性挑战:它们需要领域专业知识并仔细考虑标签的粒度、覆盖范围和一致性,并且手动注释非常耗时且成本高昂,而且也容易出现错误和偏见。此外,必须针对每个下游用例(例如,情感分析、意图检测等)重复该过程,泛化性能较差。
- 无监督机器学习法:旨在通过文本聚类、主题建模和关键词挖掘等机器学习技术来解决文本分类问题。首先以无监督或半监督的方式将语料库样本组织成簇,再通过描述学习到的簇来导出标签分类法,从而得到分类标签和分类结果。这种方法可以具有很强的扩展性和泛化性,但以可解释且一致的方式描述文本集群是极具挑战性的。
因此,作者提出了TnT-LLM,一种基于LLM的 自动化 分类生成和文本分类框架,且不需要对数据进行标注,具有较高的解释性。它被分为了两个阶段:LLM-powered taxonomy generation,LLM-augmented text classification。在第一阶段,对语料库进行小规模代表性子集采样,并受SGD迭代方式的启发,执行零样本多阶段分类法生成。在第二阶段,采样更大的数据集,并利用LLM和第一阶段生成的类别对每个实例进行分类。然后,这些 LLM 标签被视为“伪标签”,用于训练轻量级文本分类器。训练完成后,部署轻量级分类器对整个语料库进行离线标记,也可以用于在线实时分类。
2. LLM-powered taxonomy generation
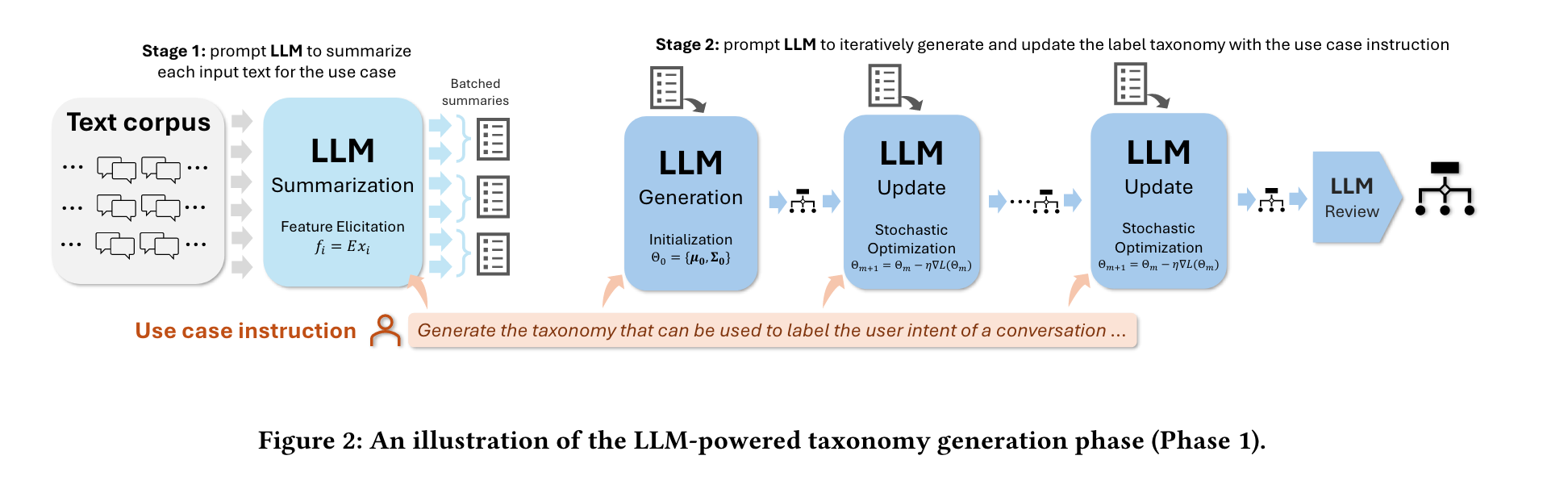
Stage 1: Summarization. we first generate concise and informative summaries of each document in the sample. Specifically, we prompt an LLM to summarize each document by providing a short blurb about the intended use-case for the summary (e.g., intent detection) and a target summary length (e.g., 20 words). This stage helps reduce the size and variability of the input documents while also extracting the aspects of the document most relevant to the use-case.
Stage 2: Taxonomy Creation, Update, and Review. We next create and refine a label taxonomy using the summaries from the previous stage. Similar to SGD, we divide the summaries into equal-sized minibatches. We then process these minibatches with three types of zero-shot LLM reasoning prompts in sequence. The first, an initial generation prompt, takes the first minibatch and produces an initial label taxonomy as output. The second, a taxonomy update prompt, iteratively updates the intermediate label taxonomy with new minibatches, performing three main tasks in each step: 1) evaluating the given taxonomy on the new data; 2) identifying issues and suggestions based on the evaluation; and 3) modifying the taxonomy accordingly. Finally, after the taxonomy has been updated a specified number of times, we apply a review prompt that checks the formatting and quality of the output taxonomy, of which the output is regarded as the final taxonomy output by Stage 1.
评估指标:Taxonomy Coverage, Label Accuracy, Relevance to Use-case Instruction
3. LLM-Augmented Text Classification
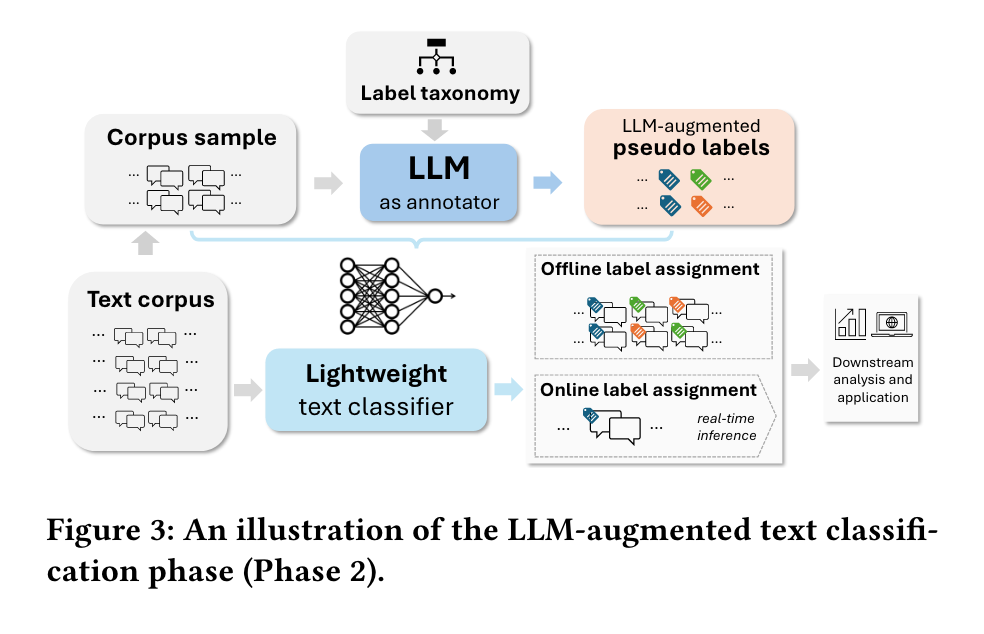
we prompt an LLM to infer the primary label (as a multiclass classification task) and all applicable labels (as a multilabel classification task) on a “medium-to-large” scale corpus sample that covers the range of labels in the taxonomy, creating a representative training dataset that can be used to build a lightweight classifier, such as a Logistic Regression model or a Multilayer Perceptron classifier.
4. 未来研究方向
- 结合LLM与embedding-based methods,以提升分类生成任务性能。
- 该框架主要用于会话领域,计划扩展到其他领域。
- 在处理数据时,需考虑隐私和道德问题。
5. 参考文献
Wan M, Safavi T, Jauhar S K, et al. TnT-LLM: Text Mining at Scale with Large Language Models[J]. arXiv preprint arXiv:2403.12173, 2024.