
基于知识图谱的大模型推理增强
图数据课程报告
摘要
大模型(Large language model, LLM)凭借其强大的涌现能力,在AI for Science、电商和生药等多个领域得到了广泛应用。然而,大模型存在幻觉、知识隐式存储等问题,如何增强其推理能力成为当前的热点研究之一。本文回顾了利用知识图谱增强LLM推理能力的相关研究,首先介绍了常见的LLM推理增强的方法,其次介绍了多种利用知识图谱增强LLM推理能力的方法,并介绍相关应用,最后提出了一些有前景的研究方向,为相关领域的研究人员提供全面的参考。
一. 引言
作为自然语言领域的一个重要分支,KG通过存储结构化的符号知识,增加知识的可解释性,在知识推理和知识融合等领域扮演着关键角色。然而,KG缺乏自然语言理解的能力,且对事实知识的泛化性较弱。相比之下,ChatGPT、Llama、ChatGLM等LLM基于海量数据进行预训练得到,不仅存储了大量数值化知识,还具备了强大的自然语言理解和生成能力,从而克服了KG在上述两个方面的不足。同时,这些LLM的出现也极大地降低了情感分析、文本分类等传统NLP任务的复杂度,使得研究焦点转向文档问答、语音识别等下游任务。
尽管LLM取得了显著成就,但其内在的限制与挑战依然不容忽视。闭源LLM的黑盒特性导致推理过程不透明,难以对模型结构及参数直接进行干预和优化。同时,庞大的参数量引发了幻觉现象,即模型在生成文本时可能产生合理但不准确或无关的输出,严重影响了推理的稳定性和准确性。此外,在面对输入上下文中的歧义、知识冲突等问题时,即使具备相关知识,LLM仍可能表现出推理能力的不足,尤其是在需要复杂多步骤推理或基于事实组合进行推断的场景中。例如,LLM在处理逆转诅咒等逻辑陷阱时显得力不从心,无法准确回答基于已有知识构建的逆向问题[1]。为了克服LLM的这些局限性,研究者们不断探索新的方法以增强其推理能力。尽管few shot learning、Chain-of-Thought(CoT)等策略在一定程度上提升了模型的推理表现,但它们往往无法从根本上解决LLM在知识整合、复杂关系推理等方面的不足。因此,将知识图谱引入LLM推理过程,成为了一个备受关注的研究热点。
利用知识图谱增强LLM推理主要可以归结为两大类方法:语义解析与检索增强。语义解析方法通过LLM将NLP问题转化为可在KG上执行逻辑查询的语句(如SPARQL),从而直接在KG中检索答案。而检索增强方法(RAG)则侧重于从知识图谱中检索相关三元组作为知识上下文,再作为LLM输入的一部分进行推理。
在这篇文章中,我们主要介绍基于知识图谱的大模型推理增强的研究进展,探讨不同方法的原理、优势与挑战,并展望未来的研究方向。
二. LLM推理增强
LLM推理增强方法可以分为四类:工具调用、检索增强、多模型决策、优化推理路径。首先,工具调用可分为两类,一类是外部工具辅助LLM的推理过程,如ChatGPT化学助手集成了通用、分子及化学反应工具[7],另一类是LLM仅起到转义作用,推理过程由外部工具完成。RAG是指在知识库中检索相关信息,作为上下文输入模型,增强推理的上下文相关性。多模型决策机制通过集成多个智能体的优势,实现推理能力的互补与提升。推理路径优化则专注于改进推理决策,包括前向推理、后向推理、归纳-演绎推理等。以上这四类并不是完全正交的,它们可以相互叠加应用,同时,知识图谱作为知识组织的强大工具,能够与各策略深度融合,进一步提升推理效能。
接下来,我们介绍了提升LLM推理能力的常见技术:
- 零样本学习(Zero shot learning):在没有任何示例的情况下推理生成的答案。研究发现,在prompt中添加”Let’s think step by step”可以显著提高LLM的推理能力。
- 少样本学习(few shot learning):在prompt中增加少量示例,尤其是负例(模型尚未掌握正确答案的示例),来提升模型的推理精度。负例的引入有助于模型学习新知识,相较于冗余的正例,其对推理能力的提升更为显著。
- CoT:不同于简单增加辅助信息,CoT方法强调在推理过程中嵌入中间步骤,引导模型逐步解析问题。这种做法不仅使推理过程透明化,便于发现并纠正错误,还显著增强了模型的推理深度和准确性。
三. 知识图谱增强LLM推理
few-shot learning 中存在知识缺失、噪声引入、知识异质性这三大挑战。首先,知识缺失源于外部知识库的不完整性,导致与特定任务相关的关键信息可能无法被检索到,从而无法为下游任务提供有用的信息。其次,并非所有的知识都对下游任务有益,不加区别地注入知识可能会导致负面的知识注入,从而引入知识噪声。最后,下游任务的语言语料库与注入的知识可能会有很大不同,导致两种独立的向量表示,即注入知识不能很好的泛化到下游任务中。为应对这些挑战,研究人员提出了OntoPrompt,包含了三个应对措施。一是采用预定义的模板技术,将基于外部KG的本体知识转换为prompt,如图1所示。二是通过修改注意力机制来筛选注入知识,从而减轻噪声。三是利用集体训练算法,同时优化下游任务的语言语料库与注入知识的嵌入表示,促进两者在向量空间中的融合与协同,增强知识的泛化能力。[2]尽管这些方法在一定程度上实现了KG与LLM的融合,但仍侧重于文本知识与嵌入优化,未能充分挖掘和利用KG中丰富的结构信息。
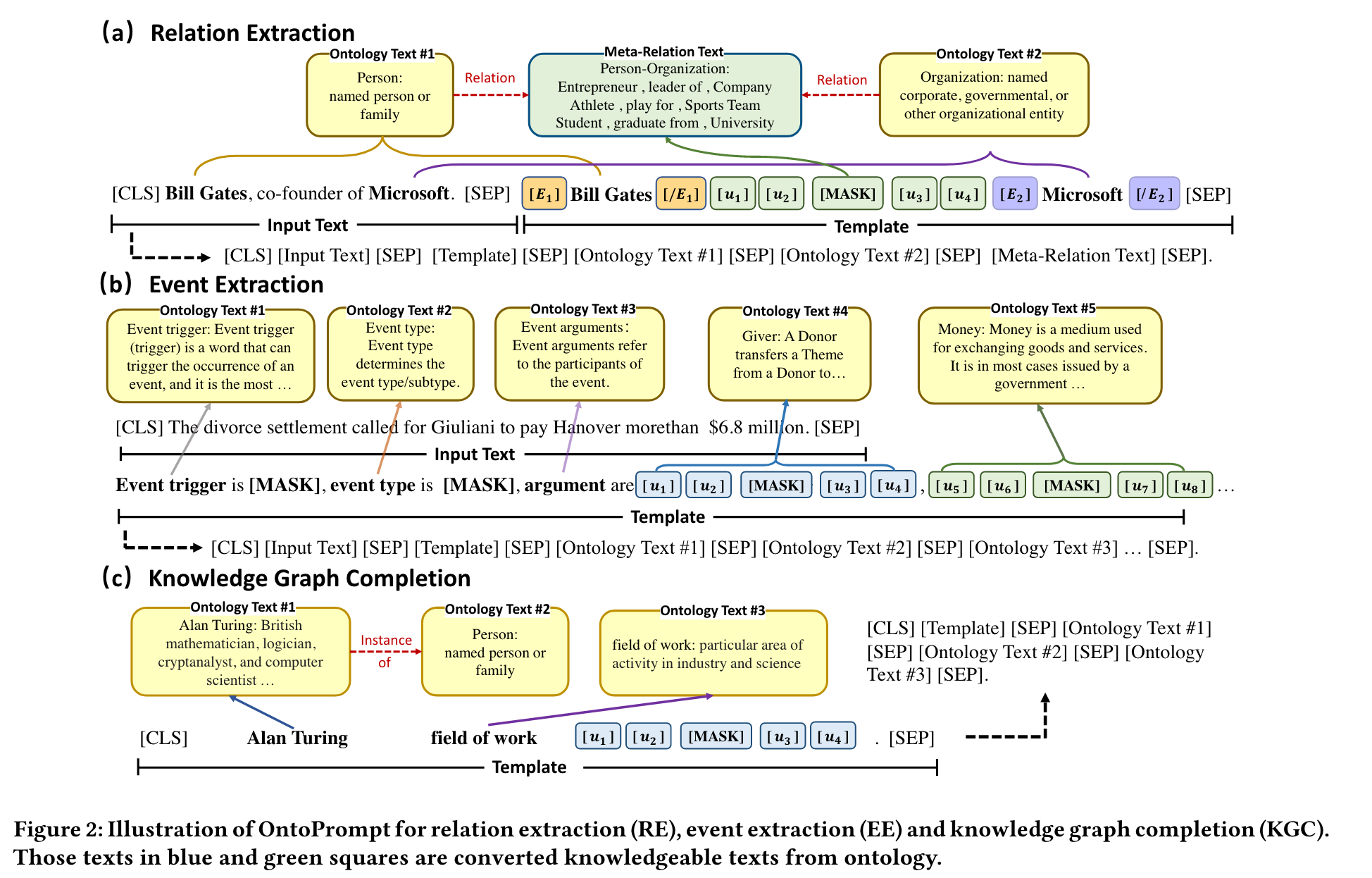
为了降低模型的推理成本、减少噪声注入,并充分利用KG中的结构信息,KP-PLM 首先根据每个句子的上下文,从相关知识库中构建了一个经过剪枝的知识子图。然后设计多个连续提示规则,将知识子图转化为提示(prompt),以增强模型的自然语言理解与推理能力。知识提示(句子转换为提示)的详细过程如图2所示。通过这种方式,KP-PLM 能够在保留关键信息的同时,显著减少在大规模知识图谱中检索的不必要开销,并降低噪声。[3]然而,该方法仅保留了 2-hop 内的相关节点,可能会忽略那些位于更远距离但同样重要的关联信息。

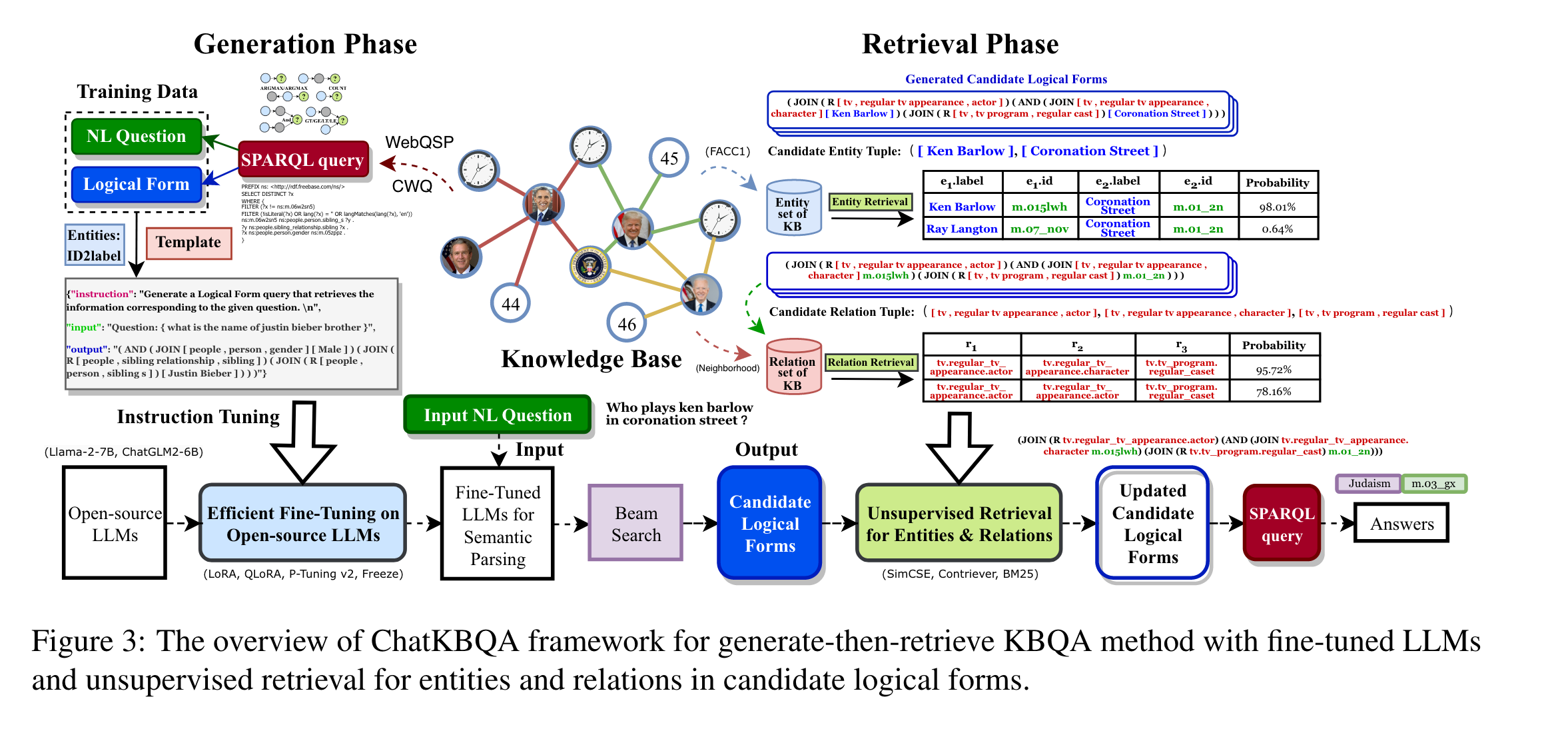
以上两种方法都是基于检索增强的方法。然而,ChatKBQA认为,RAG框架存在以下三个挑战:首先,检索效率低下,不同的KG需要采用不同的检索方法,且需要重新训练。其次,不正确的检索结果会导致错误的推理结果。最后,对于多处理步骤,使用 RAG 方法会非常复杂且易出错。ChatKBQA 采用了语义解析的方法,首先利用 LLM 生成逻辑形式,为了避免逻辑形式在KG中无法检索的情况,再通过无监督方法对实体和关系进行检索替换,从而提升推理性能。其框架如图3所示。ChatKBQA 具有灵活性(可适用于不同的基座模型和检索器)和即插即用性,并在 KBQA(Knowledge Graph Question Answering) 上实现了 SOTA 性能。[4]然而,它非常依赖于 LLM 生成的逻辑形式的准确性,无监督方法的检索替换也可能导致问题偏移,从而得到不符合要求的答案。
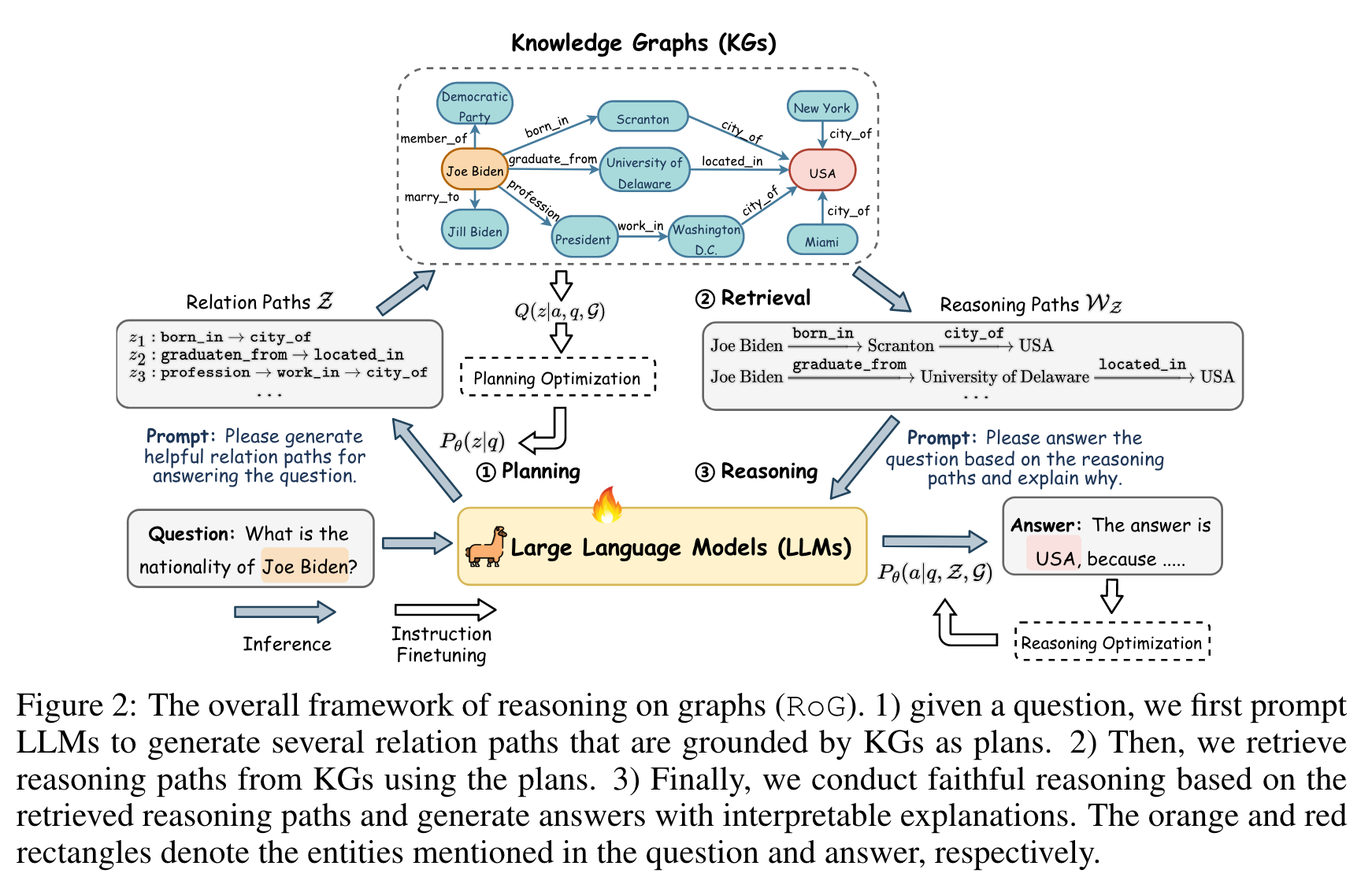
不同于ChatKBQA中利用LLM直接生成逻辑查询,RoG创新性地引入了规划-检索-推理框架,如图4所示。它首先通过LLM生成关系路径,再对KG进行检索(实体来自问题句子,关系来自LLM生成),再利用检索到的推理路径进行模型推理。该方法的独特之处在于融合了语义解析和RAG的优势,但利用LLM生成的不是逻辑语句,而是关系路径。这一转变是由于KG中的实体会不断更新变化,而关系结构相对稳定。通过训练LLM掌握关系路径的推理技巧,使得RoG模型展现出了更加高效与鲁棒的性能,实验也证实了RoG 在 KG 推理任务上的SOTA性能。[5]
与此同时,多模态知识图谱也引起了广泛的研究兴趣。UniMEL 旨在解决多模态上下文中的歧义提及(ambiguous mentions)与多模态知识图谱中的引用实体(entity)的链接问题。针对mention,充分利用图片信息和多模态语言模型(MLLM)的通用能力,将mention作为 MLLM 的输入,以获得恰当的嵌入表示。针对实体,UniMEL 认为多模态知识图谱中的实体描述包含大量不相关的信息,因此使用LLM对实体描述进行精简。 [6]通过这种方式,UniMEL 实现了较强的多模态实体链接性能。然而,该方法仅利用了多模态知识图谱中的文本和图片信息,未利用其结构信息,希望未来有更多的研究能够探索这一方面。
四. 应用
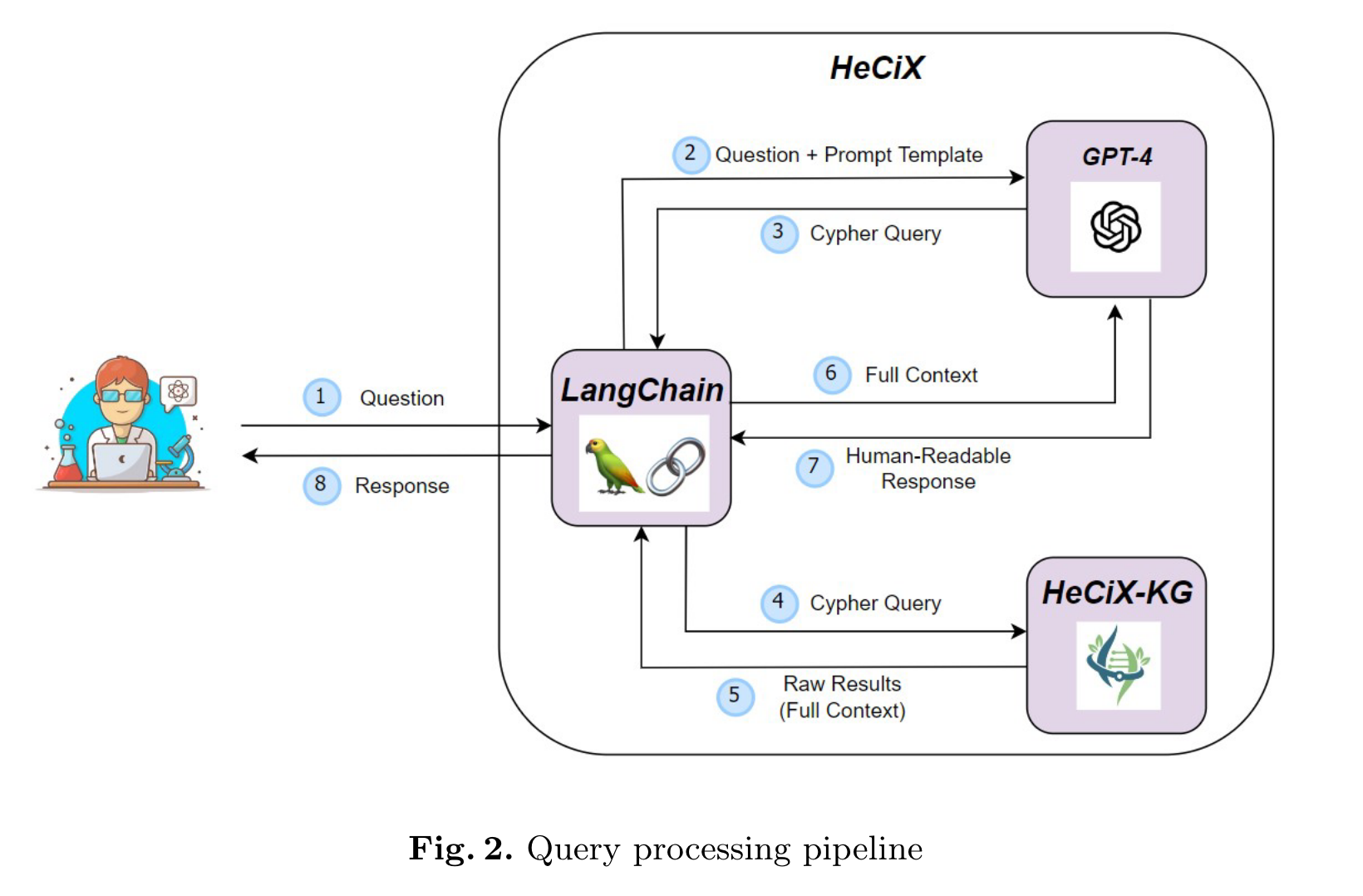
HeCiX是知识图谱在增强模型推理领域的一个典型应用,它解决了基础生物学与临床试验数据之间的鸿沟问题。Hetionet 数据库包含了关于疾病、基因和解剖学的大量领域知识,但缺乏关于先前进行的临床试验和实验的充分信息。相反,ClinicalTrials.gov 数据库提供了大量关于临床试验和全球范围内进行的实验的信息,但它对疾病本身提供了有限的见解。因此,研究者基于这两个数据库构建了 HeCiX-KG 知识图谱,并利用知识图谱增强模型推理,用于解决现实问题,其流程如图 5 所示。该方法融合了语义解析和 RAG 方法,首先利用 LLM 获取逻辑查询语句,随后在知识图谱中进行查询,最后将查询结果作为上下文输入到 LLM 中进行推理。[7]
五. 未来的研究方向
利用KG增加模型推理的透明性和可解释性。由于KG具有天然的结构化信息和语义关系,在未来的研究中,可以进一步探索如何更好地利用KG中的结构信息来增强大模型的可解释性。例如,通过可视化KG中的推理路径和节点关系,使得推理过程更加直观和易于理解。
多模态知识图谱。当前对多模态知识图谱的研究还不充分,通过大模型强大的生成能力,可以将多模态数据融合到知识图谱中,从而增强知识图谱的表达能力和推理能力。与此同时,多模态知识图谱还可以为大模型提供更加丰富和多样化的训练数据,进一步提升模型的推理性能。
强化学习和知识图谱融合。强化学习既可以减少LLM对标注数据的依赖,也可以帮助模型在复杂的推理任务中进行规划和决策,提高模型的整体推理性能。例如,在知识图谱问答系统中,RL 可以帮助模型在多步推理过程中选择最优路径,从而获得更准确和全面的答案。
动态更新和自适应能力。由于LLM知识的更新较为复杂,通过知识图谱的动态更新来保持模型知识的最新状态是一个有效的方法。在未来的研究中,可以探索使LLM能够根据KG的动态变化,自动进行prompt调整和优化的机制。
六. 总结
本文介绍了 few-shot learning 和CoT等常见的 LLM 推理增强方法,然后详细探讨了多种利用KG增强 LLM 推理能力的方法,并以 HeCiX 作为示例应用进行了介绍。最后,分析并提出了未来潜在的研究方向。我们希望这项调查能够对未来的研究工作提供指导帮助。
七. 参考文献
[1] Berglund L, Tong M, Kaufmann M, et al. The reversal curse: Llms trained on" a is b" fail to learn" b is a"[J]. arXiv preprint arXiv:2309.12288, 2023.
[2] Ye H, Zhang N, Deng S, et al. Ontology-enhanced Prompt-tuning for Few-shot Learning[C]//Proceedings of the ACM Web Conference 2022. 2022: 778-787.
[3] Wang J, Huang W, Shi Q, et al. Knowledge prompting in pre-trained language model for natural language understanding[J]. arXiv preprint arXiv:2210.08536, 2022.
[4] Luo H, Tang Z, Peng S, et al. Chatkbqa: A generate-then-retrieve framework for knowledge base question answering with fine-tuned large language models[J]. arXiv preprint arXiv:2310.08975, 2023.
[5] Luo L, Li Y F, Haffari G, et al. Reasoning on graphs: Faithful and interpretable large language model reasoning[J]. arXiv preprint arXiv:2310.01061, 2023.
[6] Kulkarni P S, Jain M, Sheshanarayana D, et al. HeCiX: Integrating Knowledge Graphs and Large Language Models for Biomedical Research[J]. arXiv preprint arXiv:2407.14030, 2024.
[7] M. Bran A, Cox S, Schilter O, et al. Augmenting large language models with chemistry tools[J]. Nature Machine Intelligence, 2024: 1-11.