
Structured information extraction from scientific text with large language models
第一作者:John Dagdelen
作者单位:Lawrence Berkeley National Laboratory
发表时间:2024/2
发表期刊:Nature Communications
关键内容:针对材料领域,使用少量数据对模型进行微调,完成命名实体识别和关系抽取任务。关键是定义了输出格式。
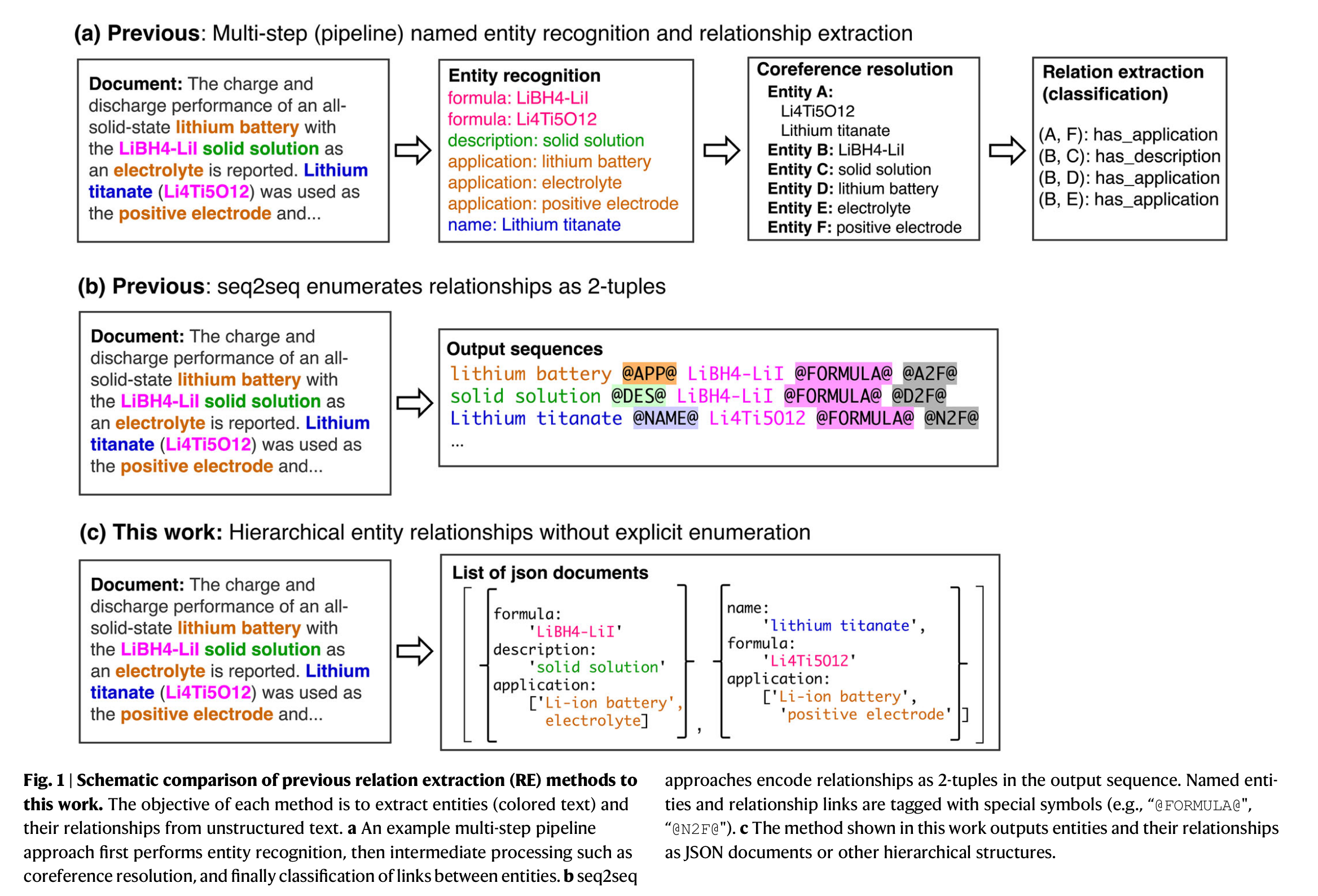
1.引言
启发:根据不同任务定义了不同的Schema、Completion format。此外,可以参照它们所使用的数据量。
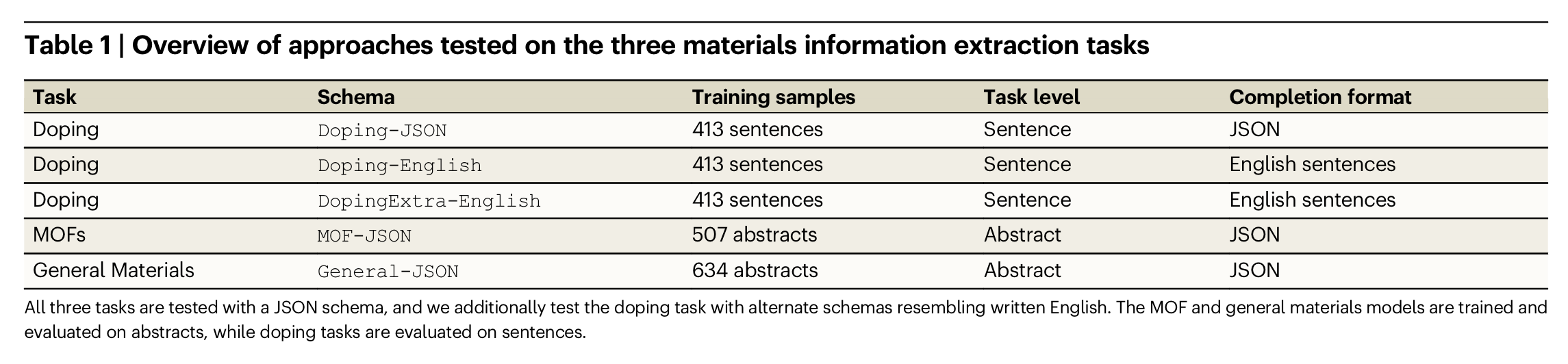
- Doping: identify host materials, dopants, and potentially additional related information from text passages (sentences).
- MOFs: identify chemical formulae, applications, guest species, and further descriptions of MOF materials from text (materials science abstracts).
- General Materials: identify inorganic materials, their formulae, acronyms, applications, phase labels, and other descriptive information from text (materials science abstracts).
2.实验结果
Schema 框架:
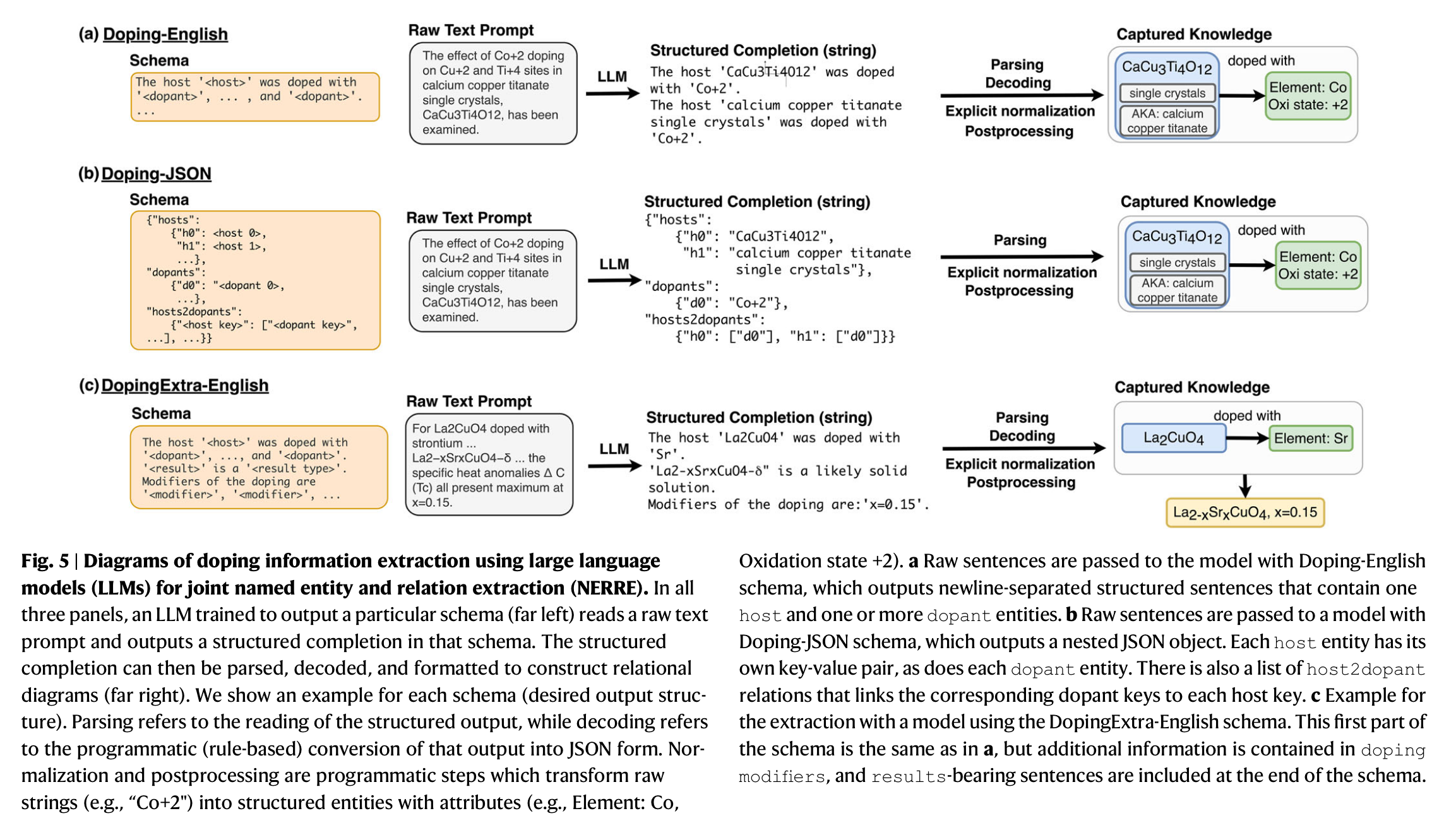
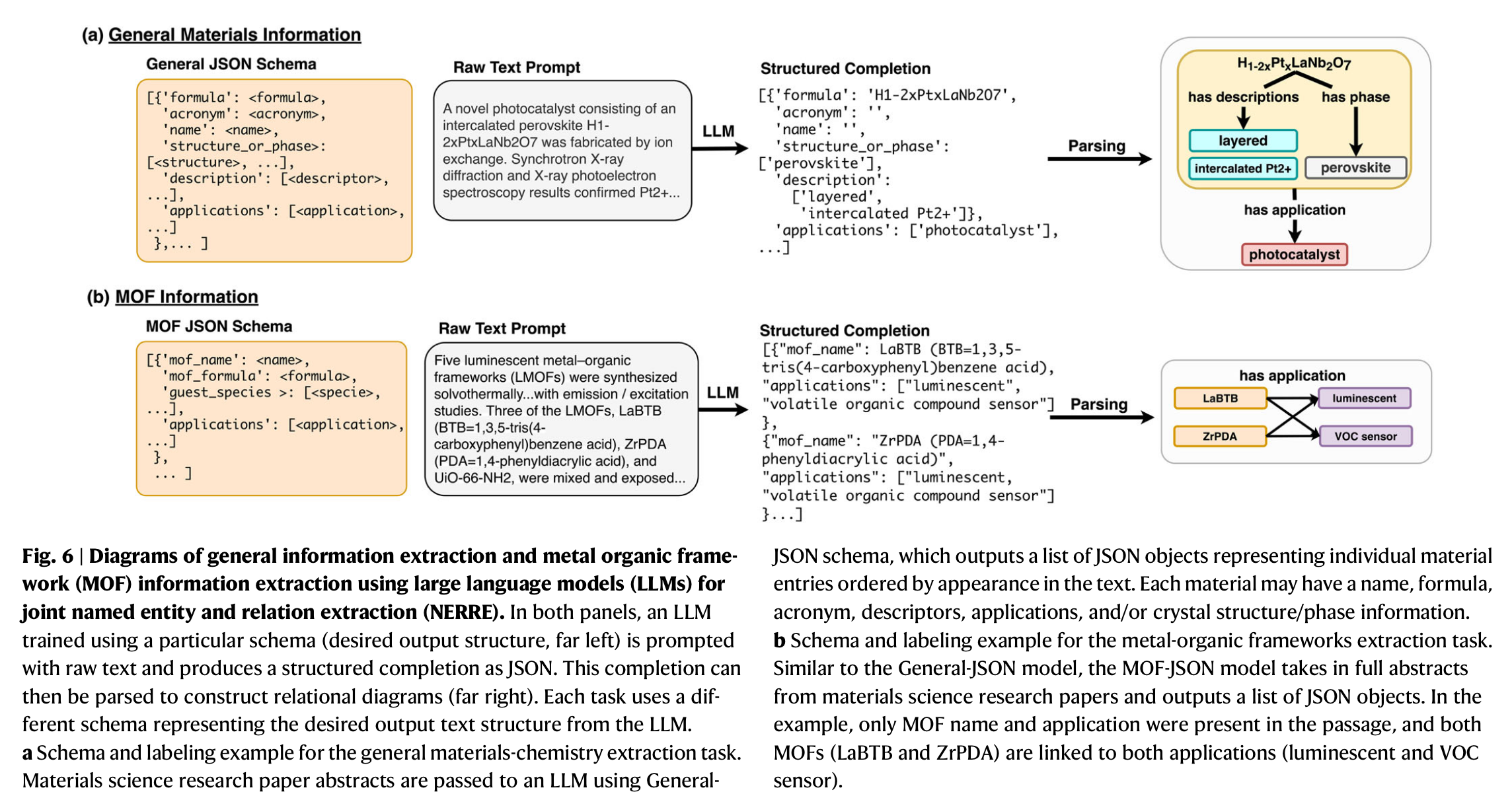
数据标注:Human-in-the-loop annotation,先利用少量样本进行训练,得到中间模型,使用中间模型对一部分数据进行标注,人工校准,得到的这部分数据又可以用于模型训练,重复这个过程。
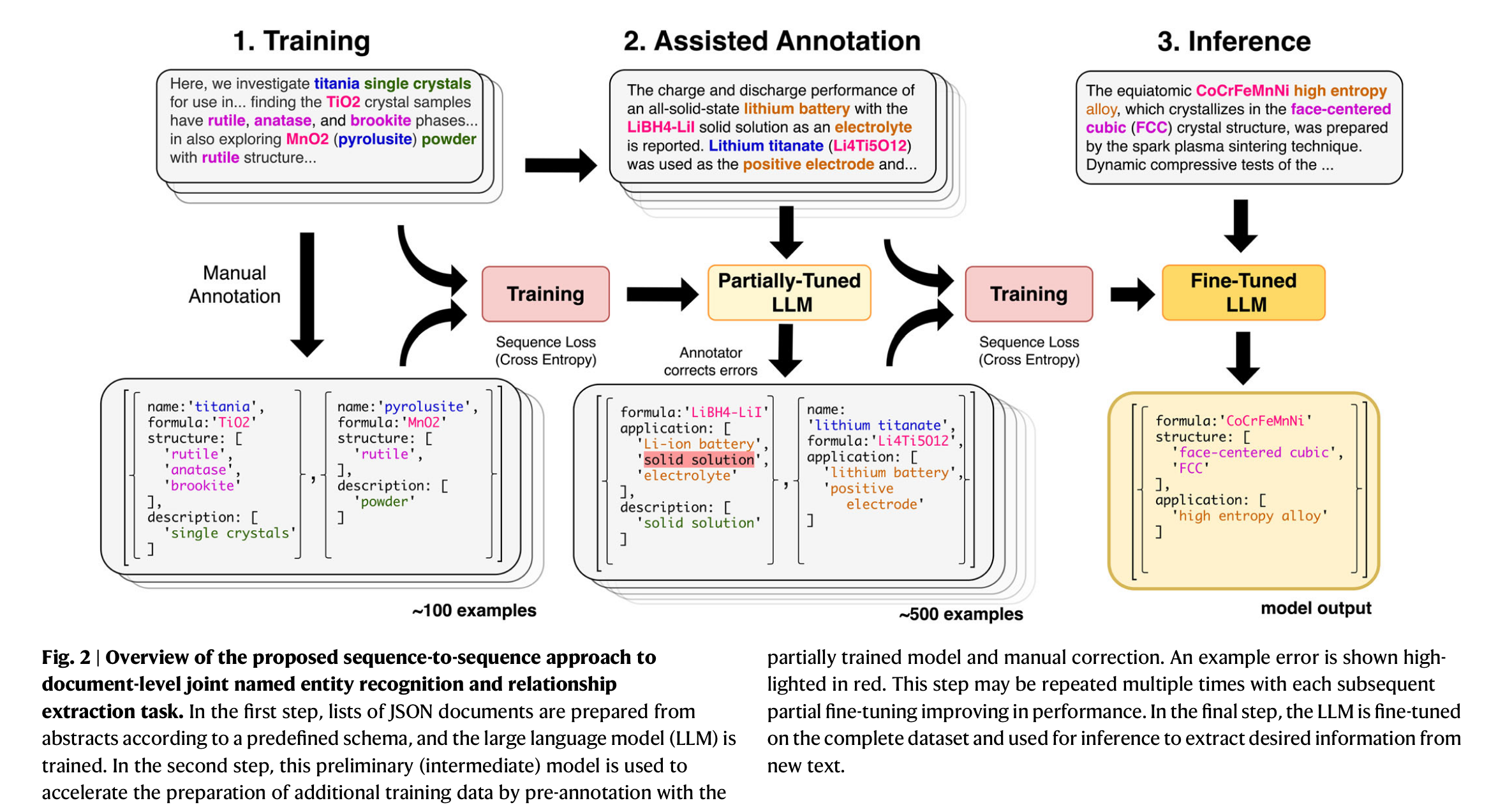
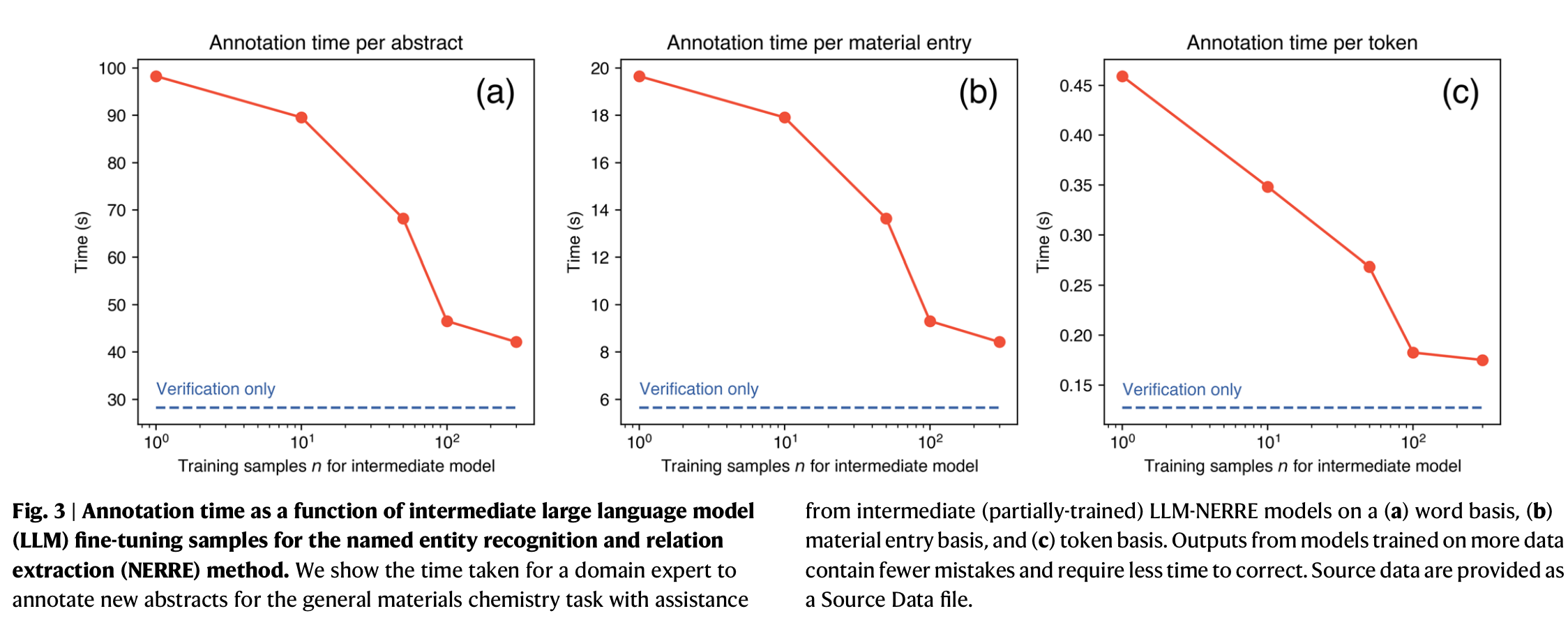
测试集:
- 掺杂数据集:训练集由162篇摘要组成,包含413个相关句子;测试集包含232句(77 relevant by regex)。
- 一般材料数据集:训练集由约650个条目组成,使用10%的随机样本进行验证,重复了五次。
- 金属有机框架数据集:训练集由507篇摘要组成,使用重复随机拆分进行评估。
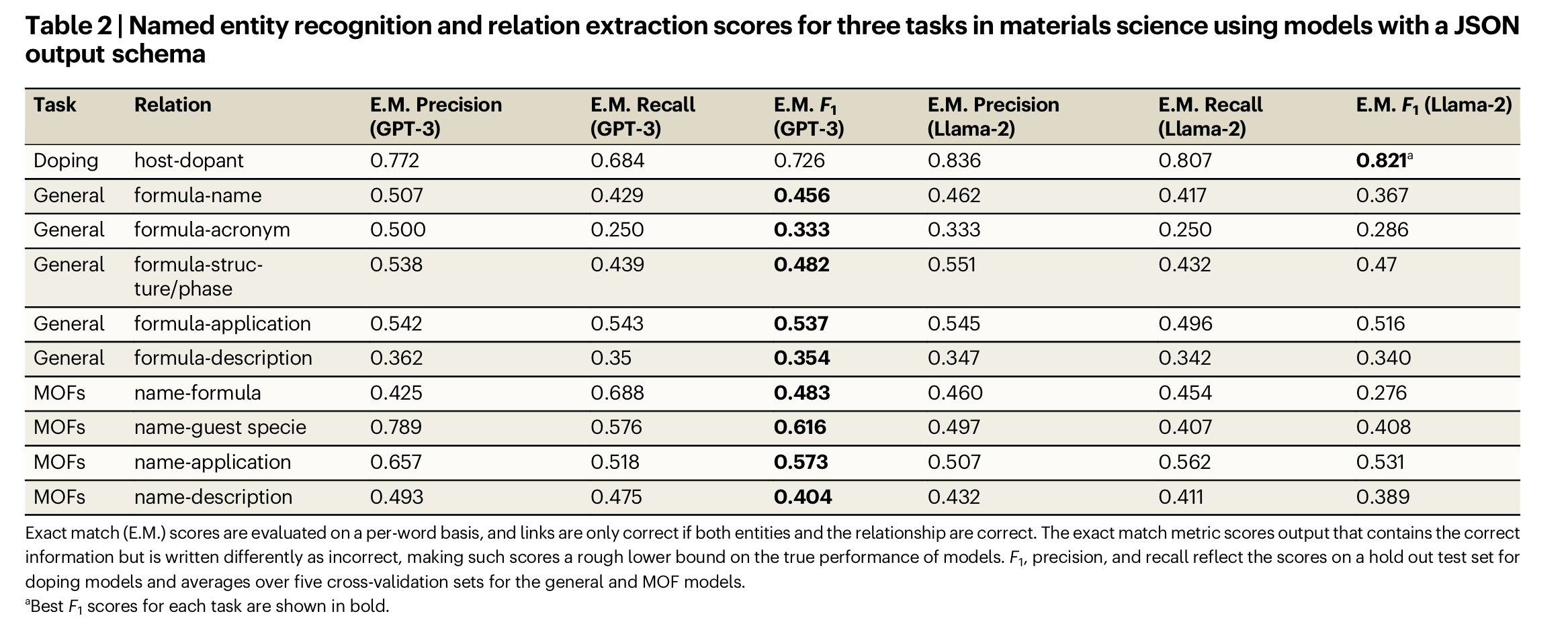
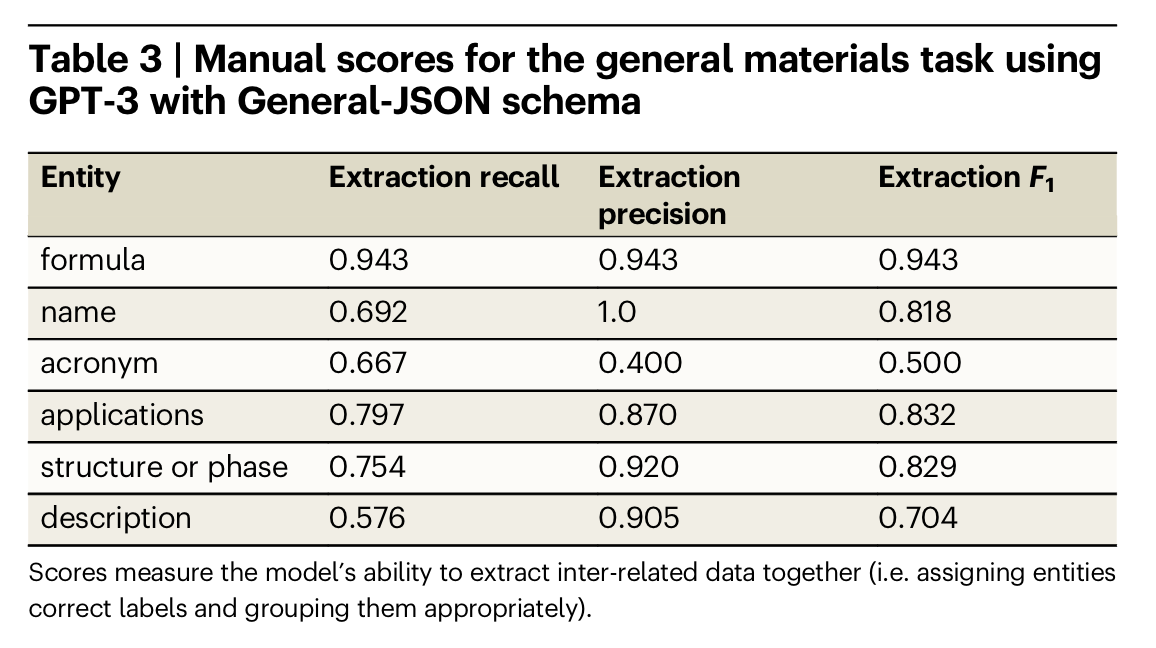
实验结果:第一张图为精确匹配的结果,即target与output中的实体取值完全一致时才判对,但由于LLM的总结能力,output中的实体取值与target不一定一致,即使它们表达的是同一个意思。第二张为人工评估的结果。
prompt + output示例:
1 | Instruction: "Your current task is to extract data from materials science research paper abstracts. Here is the JSON schema you MUST use. Only output the extracted data in this schema. Do not fill in any information that is not explicitly in the abstract. If you don’t know something from the context, just leave that spot blank (don’t guess!) Make a list of JSON objects. One for each individual material in the abstract. What is a material? A material is a chemical compound such as ’titania’, ’SiO2’, or ’graphene’. A material is NOT a device (e.g. ’valve-regulated lead/acid battery’. That would be an application). For composite materials, make one entry for each part of the composite and put the fact it’s a composite (and what composite) as one element in the description." |
3.参考文献
Dagdelen J, Dunn A, Lee S, et al. Structured information extraction from scientific text with large language models[J]. Nature Communications, 2024, 15(1): 1418.
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.